Zurück zur Startseite
ML Tooling: Dein Machine Learning Setup Leicht Gemacht
Wir machen Machine Learning für eine größere Zielgruppe zugänglich.

Der erste Teil des Posts richtet sich eher an eine technische Zielgruppe, in den Schlussabschnitten geben wir aber allgemeinere Einblicke in unseren Hintergrund und unser Setup.
Machine Learning (ML) hat sich in den letzten Jahren als ein wichtigerBestandteil in vielen Softwareprojekten etabliert. Dies stellt Entwicklungsteamsjedoch vor neue Herausforderungen, vor allem im Bereich der Infrastruktur undKollaboration. Anders als bei der Entwicklung von klassischenSoftwarelösungen, wie z.B. Mobile Apps oder Web Applikationen, spielt dasExperimentieren mit verschiedenen Ansätzen, Parametrisierungen undTechnologien eine zentrale Rolle im ML Prozess. Des Weiteren wird sichererZugriff und Verarbeitung von großen, oft sensitiven Datenmengen, Zugriff aufspezialisierte Hardware (GPUs, TPUs, ausreichend Arbeitsspeicher) unddadurch häufig die Verwendung von verteilten Cloud Ressourcen benötigt. DieEntwicklung von ML Lösungen auf dem eigenen Computer kann dabei schnellan seine Grenzen stoßen.
Quelle: What is the Team Data Science Process?
Mit unserem Projekt möchten wir einige dieser Herausforderungen undProbleme angehen und somit den Prozess des Bauens von ML Lösungen miteinem wachsenden Set an Open-Source Tools unterstützen! Ein sehr wichtigerFokus für uns ist die User-Centricity und damit einhergehend eine einfacheBedienbarkeit und Integration vertrauter Tools. Dafür setzen wir komplett aufContainerisierung mit Docker und versuchen existierende, populäre Tools sinnvoll wiederzuverwenden, miteinander zu kombinieren, zu integrieren unddurch smarte Neuentwicklungen zu ergänzen.
Mit ML Tooling kapseln wir also Komplexitäten des ML Setups und unterstützensomit Individuen, Teams und Organisationen dabei, ein professionellesInfrastruktur Setup (MLOps) aufzubauen, wodurch sich die Nutzenden auf ihreKernkompetenz und ihre eigentliche Aufgabe konzentrieren können.
Unsere Komponenten
Während der Förderung durch den Prototype Fund haben wir an der ml-tooling GitHub-Organisation weitergearbeitet, welche verschiedene Repositoriesbeinhaltet von denen wir im folgenden Abschnitt einige vorstellen. Dabei hattenwir folgende Ziele im Blick:
- Neu- und Weiterentwicklung von Open-Source Komponenten mit Fokus aufML Experimente und ML Operations.
- Verbesserung der Code- und Projektqualität durch Dokumentation undautomatisierte Build-, Test-, und Release-Pipelines. Dies vereinfacht dieWartung der Projekte nachhaltig und erleichtert es gleichzeitig derCommunity sich einzubringen.
- Erfahrungsgewinn im Aufbau von Communities und im erfolgreichenReleasen von Projekten im Open-Source Umfeld.
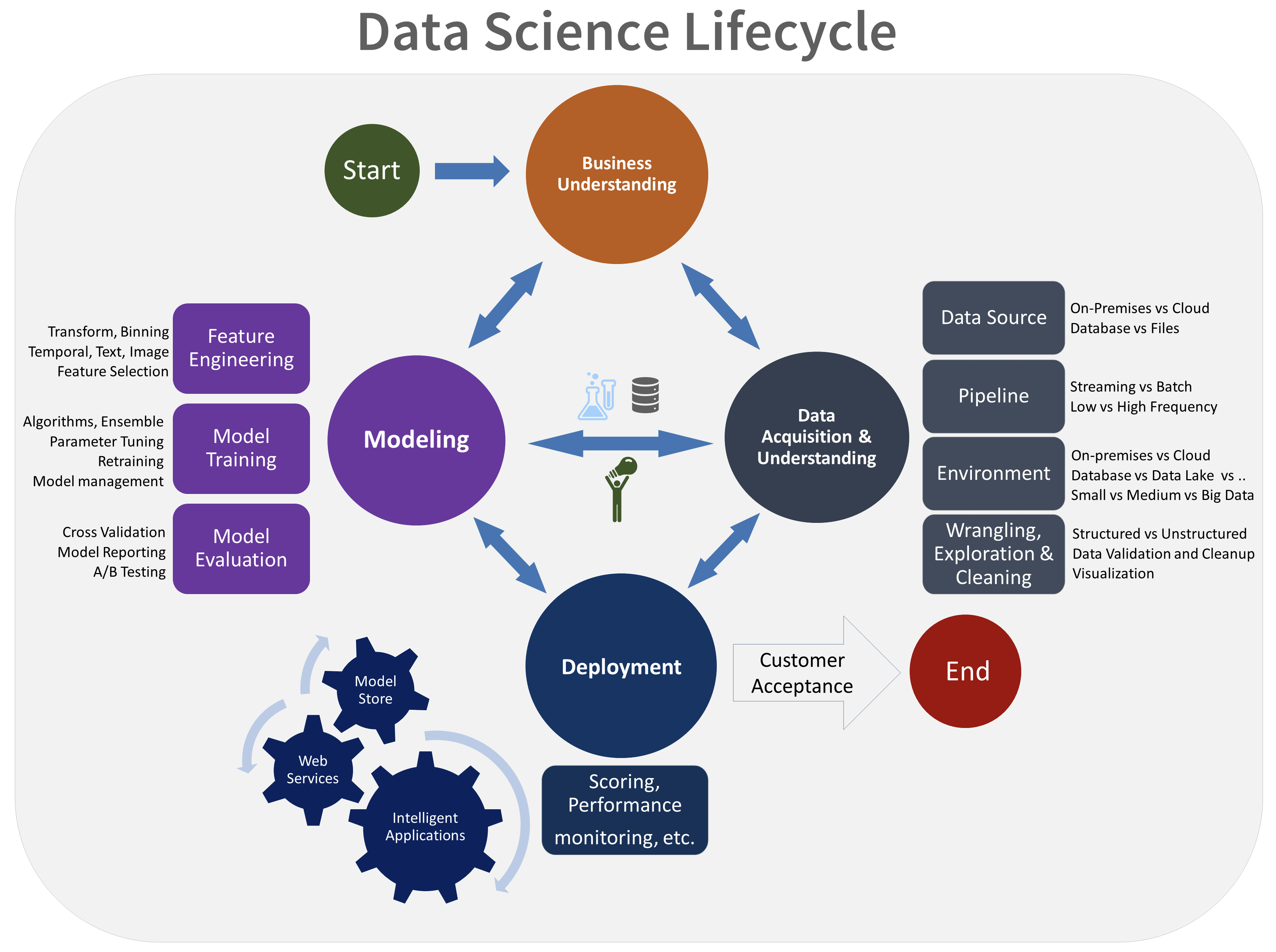
ML Workspace
Eine zentrale Komponente unserer Organisation ist der ML Workspace mitknapp 1700 Sternen (das equivalent von “Gefällt mir” in Sozialen Netzwerken)zum Zeitpunkt des Schreibens und mehreren tausend Downloads pro Tag.
Der ML Workspace ist eine all-in-one webbasierte IDE mit Fokus auf ML und Data Science. Er baut auf dem bekannten Open-Source Projekt Jupyter auf und hat eine Menge an populären Data Science Libraries (z.B. Tensorflow, PyTorch, Sklearn) und Entwicklungstools (z.B. VS Code, Tensorboard) vorinstalliert, - konfiguriert und -integriert. Dazu gehören Aspekte wie die einfache Bedienbarkeit - zum Beispiel ist das Aufsetzen einer SSH Verbindung nur einen Klick entfernt - und Sicherheit - wir haben das Jupyter Sicherheitskonzept erweitert und alle Tools innerhalb des Workspaces abgesichert. Da der Workspace zudem einfach lokal oder auf einer Cloudinstanz als Docker Container gestartet werden kann, ist die Entwicklungsumgebung innerhalb kurzer Zeit verfügbar.
Über den einfach zu konfigurierenden SSH-Zugang kann man zum Beispiel den lokalen VS Code Editor benutzen um Dateien auf einem Cloud-Workspace zu editieren und dort auch ausführen zu lassen. Wir benutzen den Workspace zum Beispiel, um auf einer Cloudinstanz zu entwickeln, Tests auszuführen und Artefakte wie zum Beispiel Docker Images zu bauen. Wenn SSH oder das Jupyter Notebook nicht ausreichen, kann der Workspace sogar über das integrierte VNC-Tool mit einer grafischen Oberfläche bedient werden. In einem Teamsetup bietet der Workspace den Vorteil, dass direkt jedes Teammitglied dieselbe Umgebung zur Verfügung hat, aber dennoch die Freiheit besitzt, Änderungen vorzunehmen.
Während des Prototype Funds haben wir mit Hilfe von Communitybeiträgen viele Bugfixes, Tool-Updates, und Verbesserungen ausgerollt. Des Weiteren haben wir den Build-, Test-, und Release-Prozess automatisiert.
ML Hub
Das ML Hub Projekt baut auf JupyterHub auf und ermöglicht die Orchestration von ML Workspaces mit Fokus auf eine Multi-User Umgebung. ML Hub ermöglicht es demnach, mehrere Workspaces zu starten und zugänglich zu machen, damit auch neben Jupyter Notebooks die vorhandenen Tools und Funktionalitäten wie zum Beispiel der SSHZugriff reibungslos funktionieren. In einem Teamsetup kann also zum Beispiel der Teamlead oder jedes Mitglied per Self-Service neue Workspaces konfigurieren und starten. So eine Konfigurationsmöglichkeit und der sich ergebende Überblick sind enorm wichtig beim Teilen und Verteilen vorhandener Computing-Ressourcen.
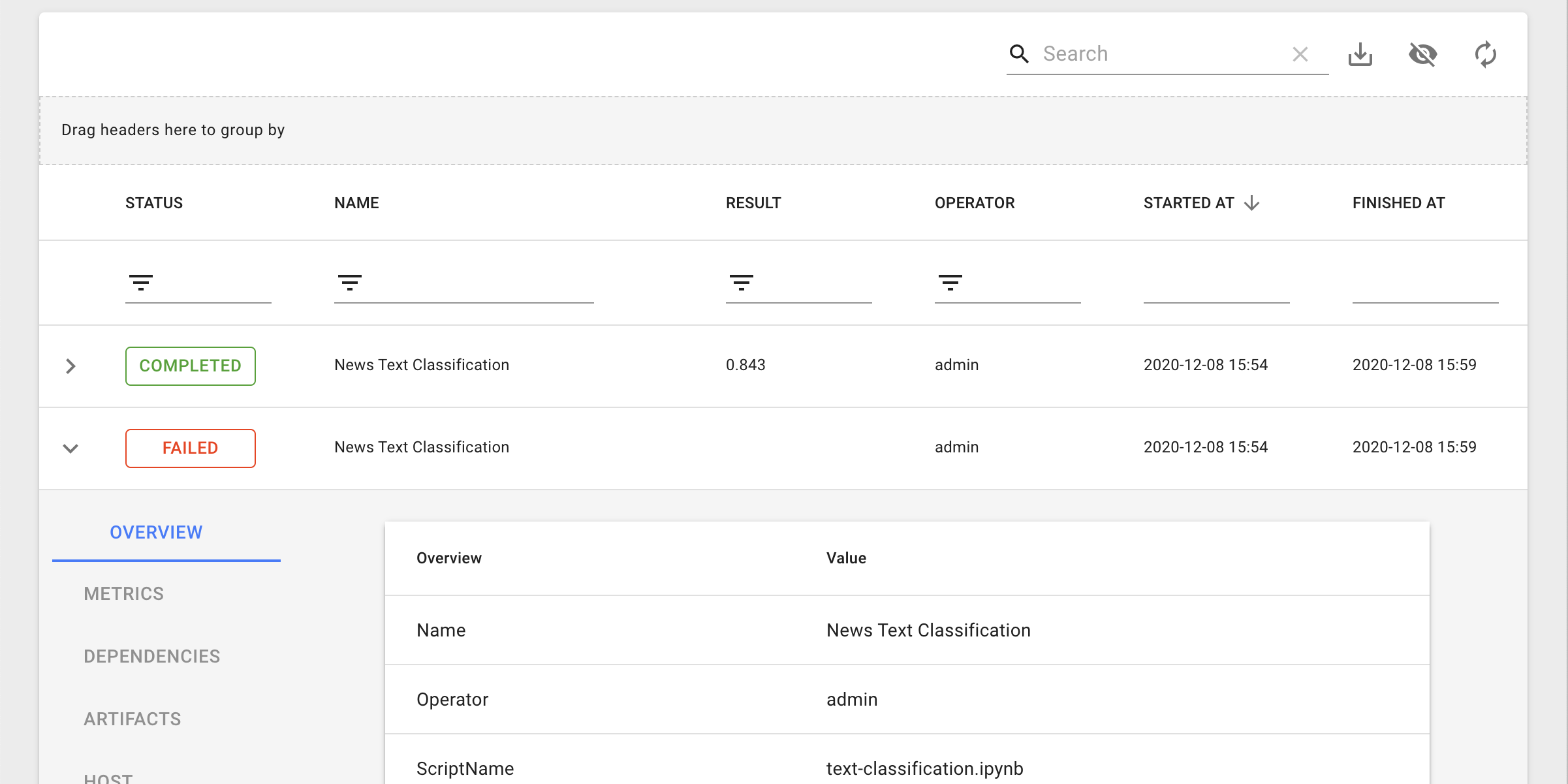
Expyriments
Wie anfangs beschrieben ist das Experimentieren häufig eine Phase eines ML Projektes. Expyriments ist eine Python Tracking Library, mit welcher Metriken und Informationen gesammelt, zentral gespeichert und dann auf einem ML Tooling: Dein Machine Learning Setup Leicht Gemacht Dashboard angezeigt werden können. Ein bekanntes Tool für das Tracken und Anzeigen von Datenreihen ist TensorBoard, welches direkt in Expyriments integriert ist. Somit ergänzen sich Expyriments und TensorBoard um eine bessere Kollaboration und Experimentenübersicht zu ermöglichen und es unter anderem einfacher zu machen, Experimente zu reproduzieren.
Lazycluster
Lazycluster ist eine experimentelle Library im Bereich verteiltes Machine Learning. Dabei werden Aufgaben auf mehrere Computer verteilt und somit Zugriff auf mehr Ressourcen ermöglicht. Dafür benutzt Lazycluster SSH Verbindungen. Lazycluster abstrahiert vorhandene Libraries des Verteilten ML Bereiches (im Moment DASK und Hyperopt) und vereinfacht im Zusammenspiel mit ML Workspaces - sehr einfaches Aufsetzen von SSH Verbindungen - das Setup der Infrastruktur. Lazycluster kümmert sich also um den Verbindungsaufbau und gibt diese Verbindungen dann zum Beispiel an DASK weiter. Da ML Workspaces beziehungsweise der ML Hub komfortabel als Container mit einem Befehl gestartet und orchestriert werden können und schon viele ML Libraries vorinstalliert sind, ist ein Setup für das verteilte Computing schnell eingerichtet; entweder auf lokaler Hardware, in der Cloud oder einem Hybrid aus beidem, was zum Beispiel bei der Nutzung von GPUs hilfreich sein kann.
Best-of
Die Best-of-Listen geben eine Übersicht über eine Sammlung an Open-Source Technologien, welche durch von uns definierten Metriken automatisch bewertet und up-to-date gehalten wird. Ursprünglich sind die Listen aus der Intention heraus entstanden, selber einen guten Überblick über das Python ML Ökosystem für unsere Projekte bekommen. Das Feedback der Community hat jedoch gezeigt, dass die Best-of-Listen für viele ein nützliches Tool für die Entdeckung und Auswahl von Technologien darstellt!
Der Fokus unserer Listen liegt auf dem Python Ökosystem, da dieses im Bereich ML mit am relevantesten ist und sich unsere Entwicklungen daher auch auf Python fokussieren. Die Python-Listen sind: best-of-ml-python (ca. 4100 Sterne), best-of-python (ca. 1400 Sterne), best-of-web-python (ca. 1000 Sterne), best-of-python-dev (ca. 180 Sterne) und best-of-jupyter (ca. 140 Sterne).

Basierend auf den Top 5 Libraries aus der Kategorie Model Interpretability aus der best-of-ml-python Liste haben wir zusätzlich diesen Blogpost veröffentlicht.
Neben des Überblicks für uns haben wir durch den Rollout auch wertvolle Erkenntnisse darüber gewonnen, wie wir unsere Zielgruppe ansprechen und erreichen können und welche Social Media Plattformen mehr oder weniger gut funktionieren.
Code- und Projektqualität
Für uns stand fest, dass wir die Code- und Projektqualität der vorhandenen Komponenten erhöhen müssen bevor wir weitere bauen, damit die Projekte auch nachhaltig gewartet werden und somit im Open-Source Bereich erfolgreich sein können. Daher haben wir am Anfang unseren Fokus auf Dokumentation und die Auswahl und Implementierung von Qualitätsmechanismen wie zum Beispiel Codeanalyse, Tests und Builds gelegt und diese Schritte weitestgehend automatisiert. Die Ergebnisse haben wir ebenfalls über eigene Repositories gut dokumentiert veröffentlicht und mit Templates unterlegt (Link), so dass wir weitere Projekte und Komponenten schnell, einheitlich und in hoher Qualität aufsetzen können und - ganz im Sinne von Open-Source - auch andere diese Erkenntnisse nutzen können.
In dem Bereich CI/CD Pipelining haben wir uns für GitHub Actions entschieden. Ausschlaggebende Punkte waren die direkte Integration mit GitHub, dass es kostenlos für Open-Source Projekte ist und es für private Projekte monatlich ein sehr großzügiges Kontingent an Freiminuten gibt. Weiterhin können die Pipelines mit dem tollen Open-source Projekt nektos/act lokal getestet werden.
Sowohl in GitHub Actions als auch in nektos/act werden Docker Container als Pipelineschritte unterstützt, was wir durch unseren Fokus auf Containerisierung sehr schätzen. Somit muss nur der Container einmal eingerichtet werden und das Setup läuft direkt in verschiedenen Umgebungen und auch auf eigenen Landschaften. Dadurch kann auch ein Vendor lock-in weitestgehend vermieden werden.
Ein weiterer Schritt für ein einheitliches Buildsystem war die Erstellung der universal-build Library.
In diese haben wir verschiedene Hilfsfunktionen ausgelagert, die wir für jede unserer Komponenten benötigen: Vom Behandeln verschiedener Command- Line Flags bis zum Bauen, Taggen und Pushen der verschiedenen Buildartefakte wie zum Beispiel der Docker Images. Weiterhin beinhaltet das universal-build Repository unter anderem unseren Standardbuildcontainer für unsere GitHub Actions Pipelines, oder auch von uns erstellte Templates für Python oder Webprojekte, sodass zukünftige Komponenten effizient auf einer sauberen Basis erstellt werden können!
Mit lazydocs haben wir noch eine Library veröffentlicht, mit welcher einfach übersichtliche, markdownbasierte Dokumentationen für Python APIs erstellt werden können!
Mit lazydocs generieren wir mittlerweile alle API Dokumentationen unserer Python Libraries bzw. Komponenten.
Neben den hier vorgestellten Projekten haben wir während der Fundingphase zu ein paar anderen Projekten, unter anderem dem oben erwähnten act, kleine ML Tooling: Dein Machine Learning Setup Leicht Gemacht Contributions in Form von Pull Requests und Issues geleistet - jede Verbesserung im Open-Source Bereich und sei es “nur” das Fixen eines Typos helfen dem Ökosystem weiter. Schau also gerne mal in unserer ml-tooling Organisation vorbei um Weiterentwicklungen und Neuheiten nicht zu verpassen und natürlich freuen wir uns auf deinen Input!
Unser Prototype Fund-Abenteuer
Wir als Team konnten in den letzten Jahren, vor allem in unserer Zeit bei SAP, einiges an Erfahrungen und Einsichten über die Herausforderungen und Probleme sammeln, welche innerhalb des gesamten Entwicklungsprozesses von ML Lösungen vorkommen. Da ein großer Teil der Innovation und Errungenschaften im ML Bereich über Open-Source Projekte stattfindet, freuen wir uns, dass wir im Rahmen des Prototype Funds dort auch einen Beitrag leisten können um diese innovativen Technologien zugänglicher zu machen.
Für Interessierte hier noch ein kurzer Überblick, wie wir während des Projektes vorgegangen sind und wie wir uns allgemein organisiert haben - vor allem, da physische Treffen durch Corona nicht wirklich möglich waren. Für einen Monat hatten wir einen OneCoworking Pass um in Berlin verschiedene CoWorking- Spaces auszuprobieren, was wir dann aufgrund des zweiten Corona-Lockdowns aufgehört haben. Zum Glück haben wir von Anfang an Wert auf Async-first und Remote-first gelegt und versucht, einen dokumentationsbasierten Ansatz zu leben (unter anderem inspiriert von Amazons berühmten Silent Meeting): Wir haben Notizen und Gedanken immer schriftlich festgehalten (wir benutzen Notion dafür) und basierend auf den niedergeschriebenen Notizen erste wichtige Entscheidungen getroffen. Daraufhin haben wir die Ergebnisse der Entscheidung beziehungsweise das Konzept sauber und strukturiert ausformuliert und dort dann kommentiert, diskutiert und letztlich kollaborativ feingeschliffen.

Unsere Tools
Weitere Tools, welche für unser Remote Setup sehr hilfreich waren, sind VS Code mit seinem Live Share Plugin für Remote Pair Programming, Notion für Notizen und Planung, Todoist für feingranulare Aufgaben, Remotion und CoScreen für Video Calls und Screen Sharing Sessions sowie Slack für Kommunikation. Ein letzter, hoffentlich hilfreicher Tipp: Durch das Öffnen eines Geschäftskontos bei Penta haben wir $5000 AWS Credits bekommen.
Wir hoffen, dass diese Liste für den ein oder anderen eine Inspiration ist! Vielleicht veröffentlichen wir in Zukunft mal eine aufgeräumte Liste idieser ganzen Tools mit mehr Hintergrundinformationen und Details.
Die nächsten Schritte
Unsere Prototype Fund-Phase nähert sich jetzt leider schon dem Ende, aber die gute Nachricht ist: unsere Arbeit an ml-tooling geht weiter! Das positive Feedback der Community zeigt uns, dass die Projekte einen echten Mehrwert liefern und das motiviert uns natürlich, die Projekte weiter voranzutreiben. Wir arbeiten unter anderem aktiv an einem weiteren Open-Source Tool mit Fokus auf Experimentation, Operation & Kollaboration im ML und Data Engineering Bereich. Dieses integriert die hier vorgestellten Komponenten und ermöglicht es durch ein flexibles Erweiterungssystem beliebige Tools aus dem ML Ökosystem mit sehr geringem Aufwand in den eigenen Workflow einzubinden. Bleibt gespannt!
Wir möchten uns an dieser Stelle beim Prototype Fund, vor allem bei Marie, Thomas und Patricia, für die gemeinsame Zeit und Unterstützung bedanken nund für die Freiheit, innerhalb des Programms verschiedene Dingen Unsere Tools ML Tooling: Dein Machine Learning Setup Leicht Gemacht ausprobieren zu können, beim DLR als Projektträger und beim BMBF für die Förderung!
Mit ❤ -lichen Grüßen aus Berlin,