
Zurück zur Startseite
OpenRedact - Dokumente teil-automatisch anonymisieren
Wir bereinigen Dokumente von personenbezogenen Daten.
Die Anonymisierungs-App OpenRedact bereinigt Dokumente von personenbezogenen Daten. Der Anonymisierungsleitfaden gibt einen Überblick zur Anonymisierung von amtlichen Werken.
Der Wunsch Open Data zur Verfügung zu stellen, kollidiert häufig mit dem Datenschutz. Das Bewusstsein für Datenschutz ist seit der Datenschutz-Grundverordnung (DSGVO) gestiegen und stellt eine Herausforderung nicht nur für die Entwicklung neuer Geschäftsmodelle, sondern auch für Open Data dar. Der große Aufwand staatlicher Stellen, ihre Daten für die Veröffentlichung zu anonymisieren steht dem Interesse der Bürger*innen nach Transparenz gegenüber. Die manuelle Anonymisierung von Daten ist teuer und sehr zeitaufwändig.
OpenRedact hat sich das Ziel gesetzt, den Aufwand der Anonymisierung von deutschsprachigen Texten und Dokumenten zu reduzieren. Dadurch soll die effiziente Veröffentlichung von Open Data ermöglicht und Datenschutz sichergestellt werden.
Anonymisierungsrichtlinie
OpenRedact hat während des Förderzeitraums nicht nur an einer technischen Applikation gearbeitet, sondern auch einen Anonymisierungsleitfaden für Open Data entwickelt. Dieser Anonymisierungsleitfaden soll Behörden und der Justiz das Vorhaben von Open Data unter Wahrung des Datenschutzes ermöglichen. Grundsätzlich sind personenbezogene Daten zu anonymisieren. In unserem Leitfaden befassen wir uns mit den verschiedenen Methoden der Unkenntlichmachung von personenbezogenen Daten und schauen uns zwei Anwendungsfelder an. Die Anwendungsfelder betreffen Informationsfreiheitsgesetzanfragen und die Veröffentlichung von Urteilen. Wir zeigen auf, dass die semi-automatisierte Anonymisierung die Behörden bei dem Schutz personenbezogener Daten entlasten kann. Am Ende des Leitfaden schlagen wir vor, wovon es abhängig sein soll, ob personenbezogene Daten anonymisiert, pseudonymisiert oder mit Hilfe von Differential Privacy unkenntlich gemacht werden. Hierzu haben wir ein sogenanntes Abstufungskonzept entwickelt, was die Anwendung von OpenRedact von dem Inhalt abhängig macht. Die letztendliche Entscheidung, welche Methodik Anwendung findet, bleibt eine manuelle; ebenso die letzte Überprüfung nach dem Einsatz von OpenRedact. Ähnliche semi-automatisierte Anonymisierungstechniken wie in der Schweiz zeigen eine erhebliche Arbeitserleichterung.
Übersicht
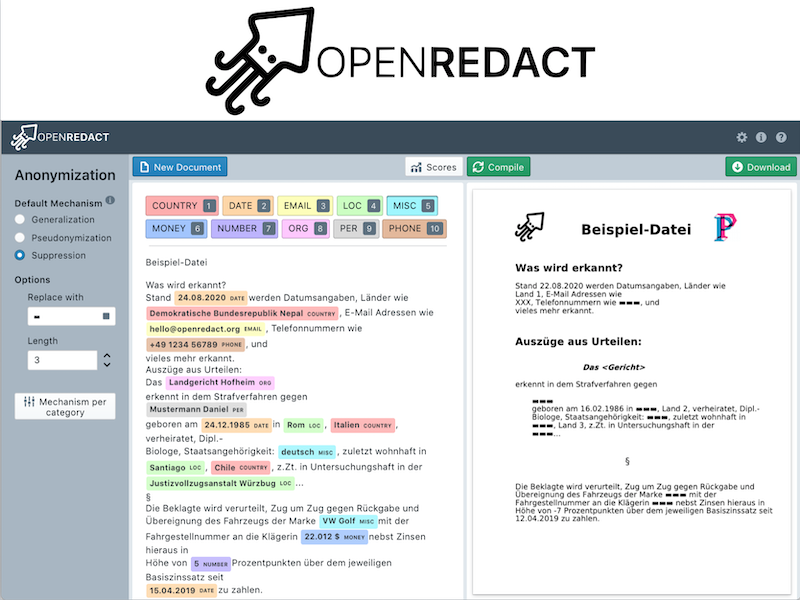
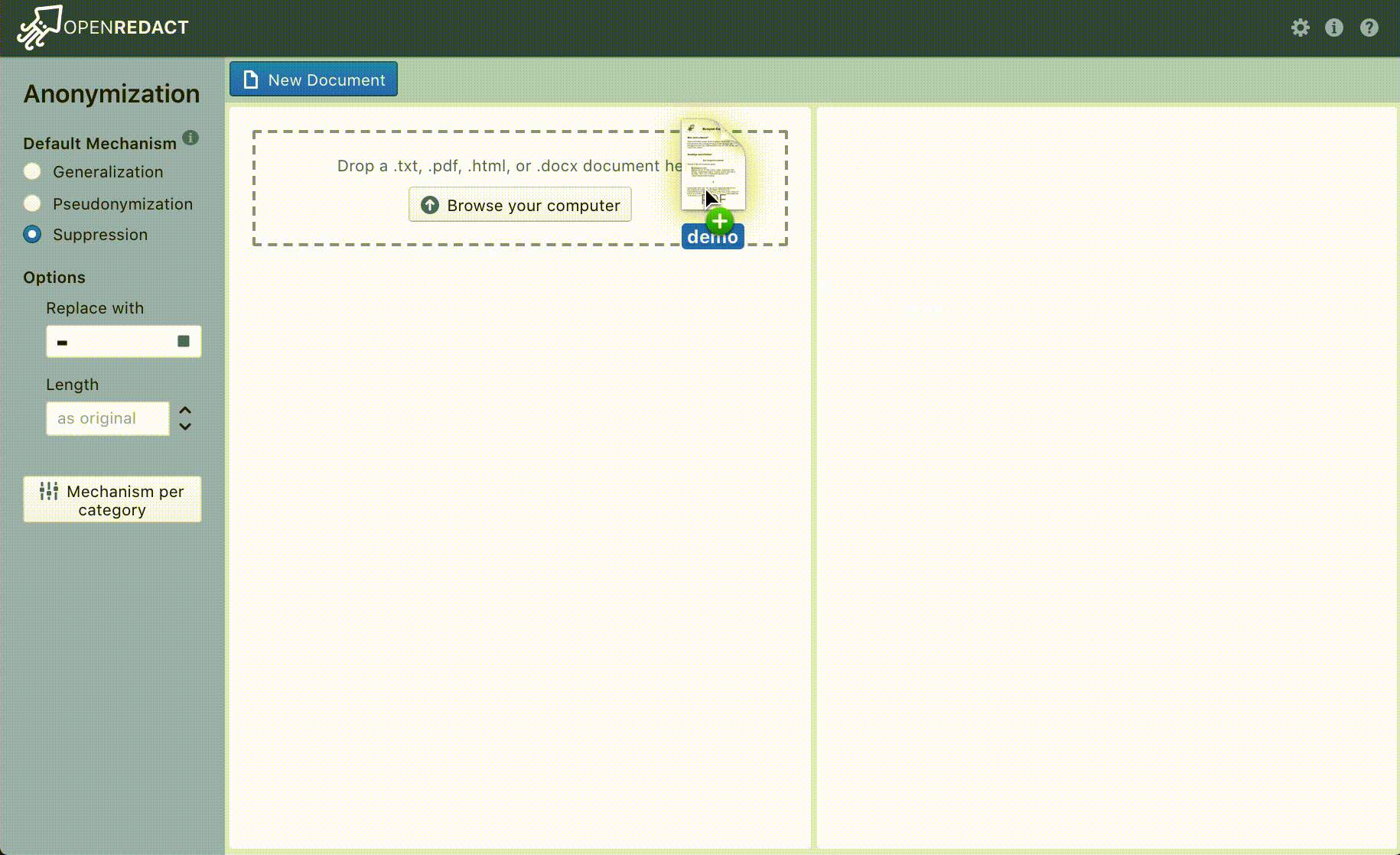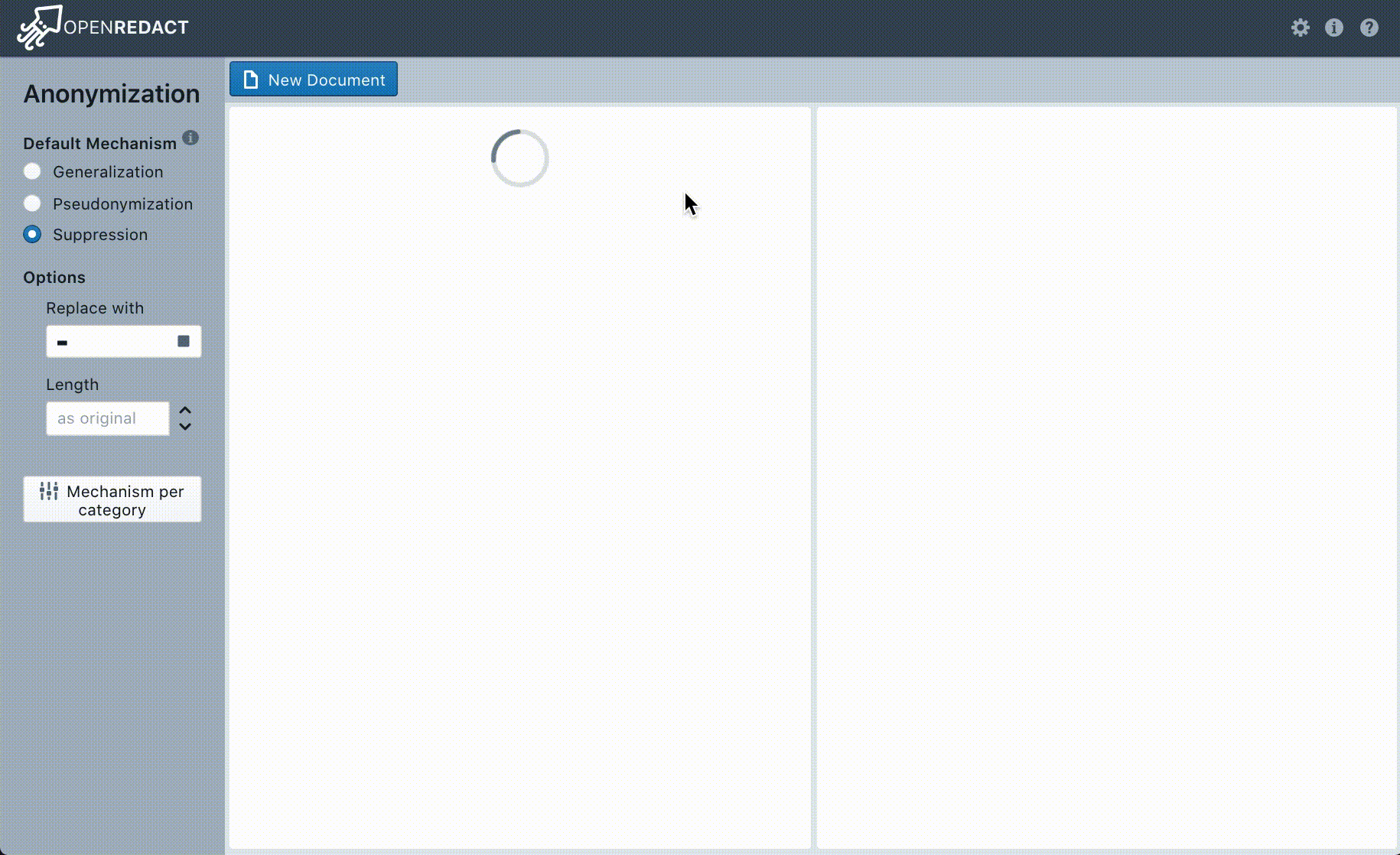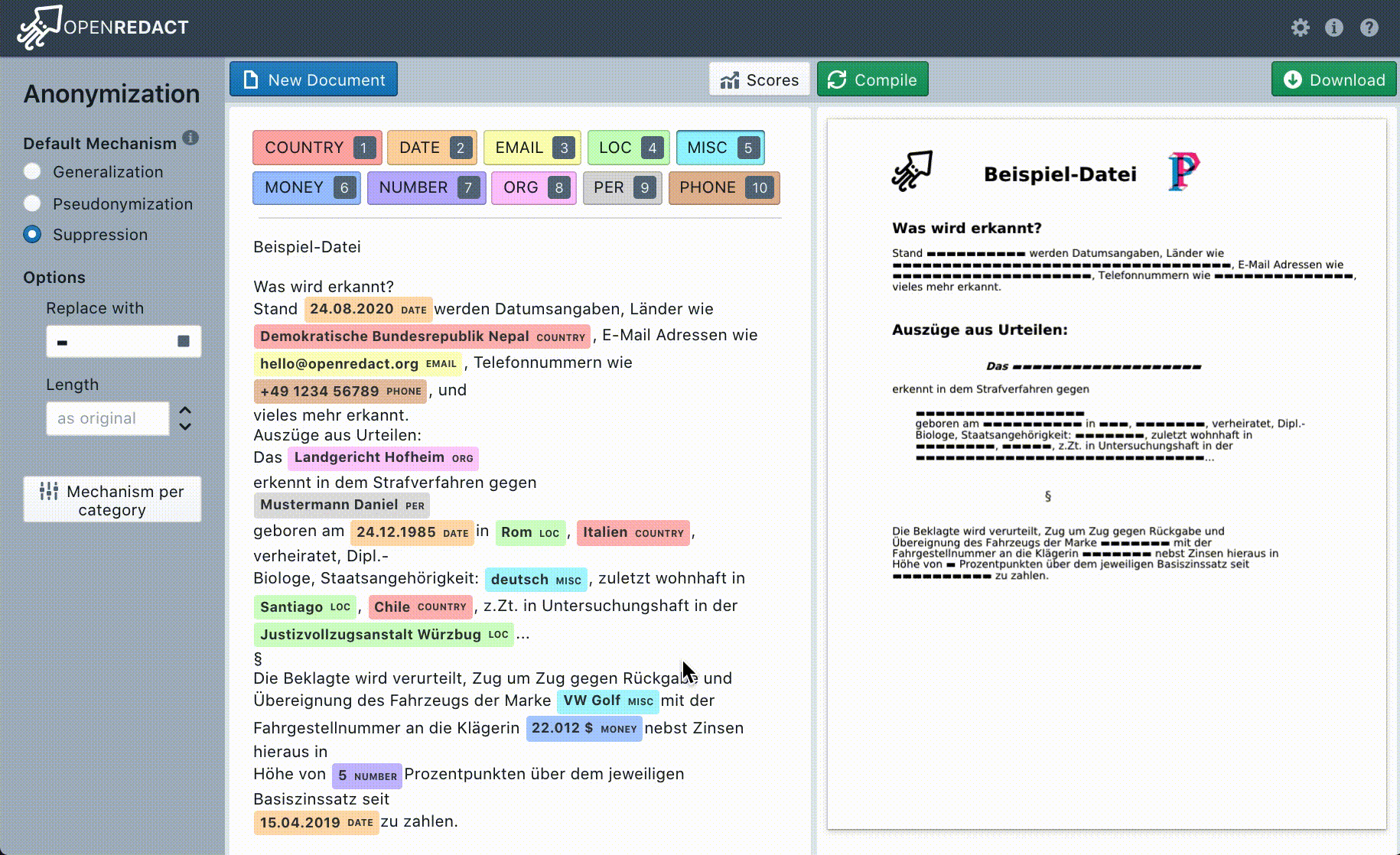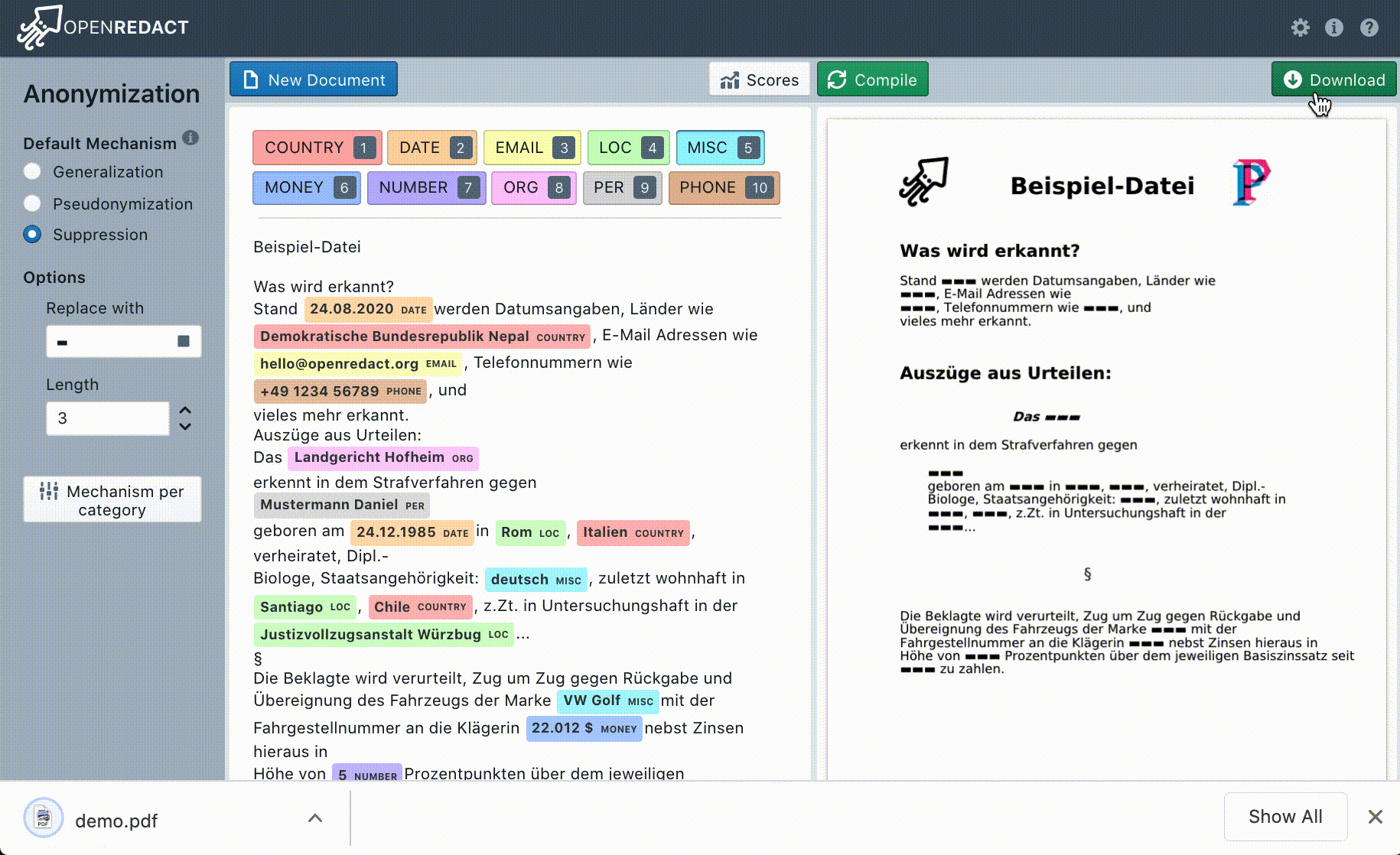
OpenRedact hat eine Web-App entwickelt. Über diese Web-App können die zu anonymisierenden Dokumente in verschiedenen Dateiformaten hochgeladen werden. Dabei werden gängige Formate wie DOCX (MS-Word) und PDF aber auch Plain-Text (.txt) unterstützt. Nach dem Hochladen wird das Dokument automatisch auf personenbezogene Daten wie Namen, Geburtsdatum oder Adresse geprüft. In der Bearbeitungsansicht können dann fehlende personenbezogene Daten korrigiert und Einstellungen festgelegt werden. Bei jeder Änderung erscheint automatisch eine Vorschau, die anzeigt wie das Ergebnis aussehen wird. In einem letzten Schritt müssen Nutzer*innen nochmals alle Änderungen überprüfen, insbesondere ob tatsächlich alle personenbezogenen Daten gelöscht bzw. unkenntlich gemacht wurden. OpenRedact kann nicht gewährleisten, dass eine vollständige und fehlerfreie Anonymisierung vorgenommen wird. Erst nach den letzten Korrekturen der Nutzer*innen, kann die anonymisierte Version heruntergeladen werden. Durch die Bearbeitungsansicht geben wir die volle Kontrolle an die Nutzer*innen. Zusätzlich kann über die Einstellungen zwischen verschiedenen Anonymisierungsmethoden (Pseudonymisierung oder Anonymisierung) gewählt werden. Alle während der Anonymisierung anfallenden Daten werden nicht dauerhaft gespeichert.

Komponenten
Auf technischer Ebene haben wir OpenRedact in unabhängige Komponenten gegliedert. Jede einzelne Komponente erfüllt eine eigenständige Aufgabe und kann dadurch unabhängig von OpenRedact einen Mehrwert liefern. Auf diesem Wege fördern wir die langfristige Nachnutzung der im Projekt entstandenen Software.
Web-App
Als Benutzeroberfläche wurde eine Web-App auf Basis von ReactJS entwickelt. Der Bearbeitungsmodus nutzt react-text-annotate und zum Anzeigen von PDFs wird auf react-pdf bzw. pdf.js zurückgegriffen. Das Backend basiert auf dem FastAPI Framework. Durch die Trennung von Front- und Backend kann die Anonymisierungssoftware nicht nur über die Web-App sondern auch direkt über eine RESTful API und eine CLI genutzt werden. Zudem erlauben Docker-Container die Nutzung von OpenRedact auf der eigenen Infrastruktur mit einem einfachen docker-compose up.
Unterstützung von Dokumentenformaten
Um personenbezogene Daten in Dokumentenformaten erkennen zu können, muss der in den Dokumenten enthaltene Text extrahiert werden. Allerdings muss der Text nicht nur extrahiert sondern auch modifiziert werden: Wurden personenbezogene Daten gefunden, dann müssen diese auch anonymisiert, also entfernt oder ersetzt werden. Nach dem bisherigen Kenntnisstand von OpenRedact gibt es kein Tool, welches das Modifizieren von mehreren Dokumentenformaten auf Zeichen- oder Wortebene erlaubt. OpenRedact hat diese Lücke mit der Python Bibliothek ExposeText geschlossen. Es werden beide Funktionalitäten zusammengefasst: ExposeText legt den Text-Inhalt eines Dokumentes zum Lesen und Verändern frei. Das Ändern von Dokumenten wird damit so einfach wie das Ändern eines Python Strings. Anhand des Zeichenindex im extrahierten Text kann einer Passage direkt ein neuer Wert zugewiesen werden. Die durch das Dokumentenformat definierte Formatierung der Passage bleibt dabei erhalten. Prototypisch unterstützt werden Dokumente in den Formaten .txt, .html, .docx und .pdf. In unserem Blogpost zu ExposeText beschreiben wir die Bibliothek näher.
Erkennung von personenbezogenen Daten
Personenbezogene Daten lassen sich mit Methoden der Named-entity recognition (NER) identifizieren. Häufig werden Regeln für reguläre Ausdrücke definiert oder Deep-Learning-Modelle auf einem Korpus von annotierten Texten trainiert. Der Deep-Learning-Ansatz hat in den letzten Jahren große Fortschritte erzielt, allerdings liegt der Fokus der Forschung und Entwicklung auf der englischen Sprache und verfügbare vortrainierte Modelle im Deutschen sind weniger leistungsfähig.
Um die besten Ergebnisse für die deutsche Sprache zu erzielen, kombiniert unsere Bibliothek NERwhal deshalb verschiedene Methoden: NERwhal erkennt Entitäten mit Hilfe von regulären Ausdrücken, Deep Learning, sowie spaCy’s Entity Ruler und dem FlashText Algorithmus.
Die Vielfalt der Kontexte und Domänen, in denen personenbezogene Daten auftreten können, ist groß und es ist schwierig alle Daten zu finden, ohne nicht-personenbezogene Daten fälschlicherweise mit zu erfassen. Deswegen müssen die Erkennungsmethoden üblicherweise spezifisch für einen Sprachraum oder eine Art von Dokumenten sein. Statt den Fokus auf eine Art von Dokumenten zu legen, haben wir eine universell nutzbare Suite für NER gebaut, die das Ziel hat, dass Nutzer*innen schnell eigene Erkennungsmethoden für die spezifischen vorliegenden Daten schreiben können. Für deutsche Dokumente haben wir beispielhaft die Erkennung für folgende Kategorien von personenbezogenen Daten umgesetzt: Personen, Orte, Organisationen, Geldbeträge, E-Mail Adressen, Telefonnummern, Zahlenwerte, Länder, Datumsangaben und Verschiedenes.
In Zukunft wäre es möglich, die manuellen Annotationen als Trainingsdaten für die statistischen Modelle zu benutzen. Somit könnten die Anwender*innen die Erkennung auf ihren Daten schrittweise verbessern und dadurch den manuellen Aufwand reduzieren. Weitere Details wie die Kombination der Ergebnisse und das Nutzen von Wörtern, die häufig im Kontext der Entität vorkommen, werden im NERwhal Blogpost beschrieben.
Anonymisierung von personenbezogenen Daten
Um die persönlichen Daten innerhalb eines Textes zu schützen, werden verschiedene Anonymisierungstechniken verwendet. Die Anonymisierungstechniken sind in einer eigenen Bibliothek zusammengestellt. Die Anonymizer Bibliothek kann bei Bedarf auch um weitere Methoden erweitert werden. Aktuell sind integriert: das Anonymisieren, das Pseudonymisieren und auch das Verrauschen von Textbestandteilen (sog. Differential Privacy).
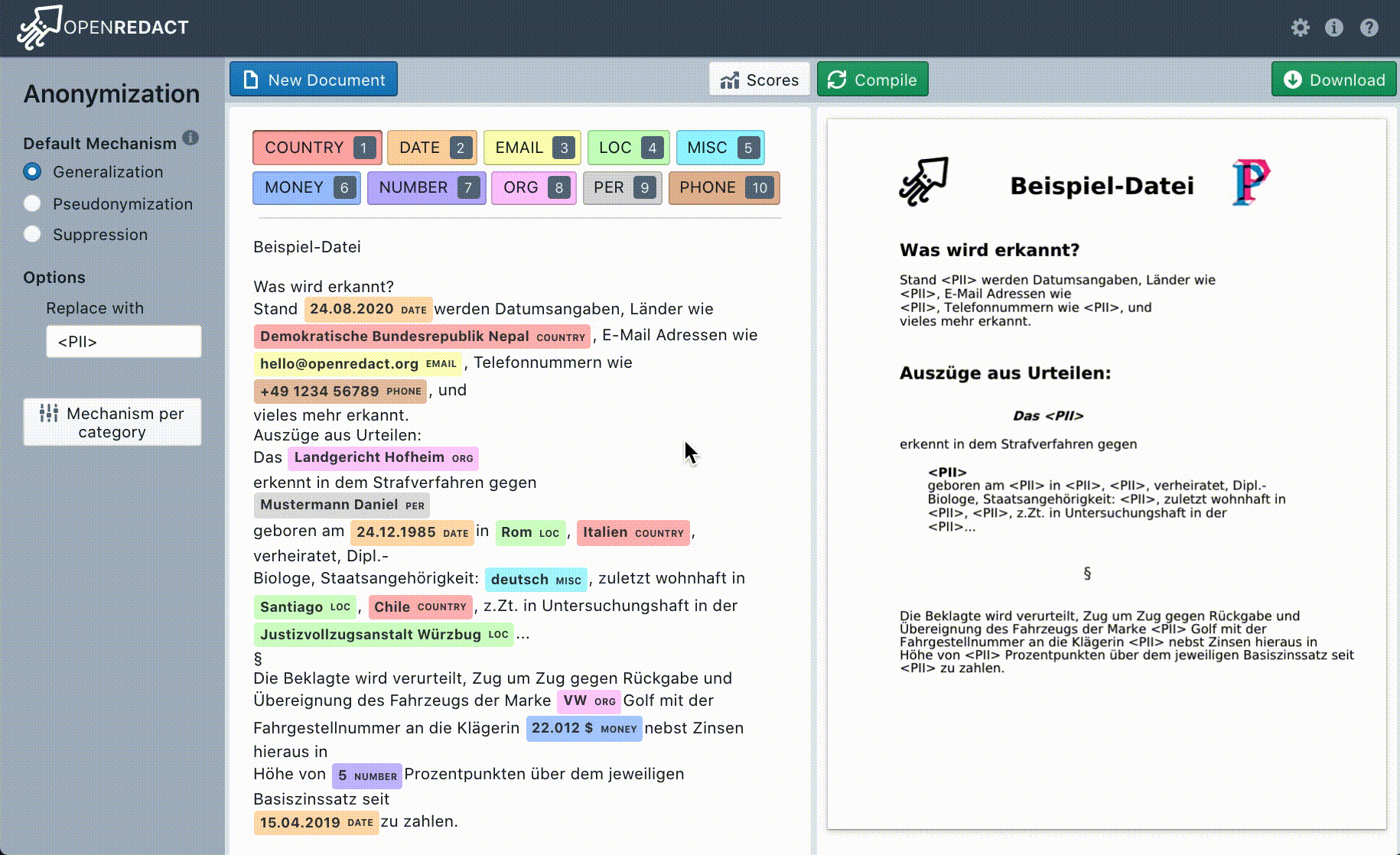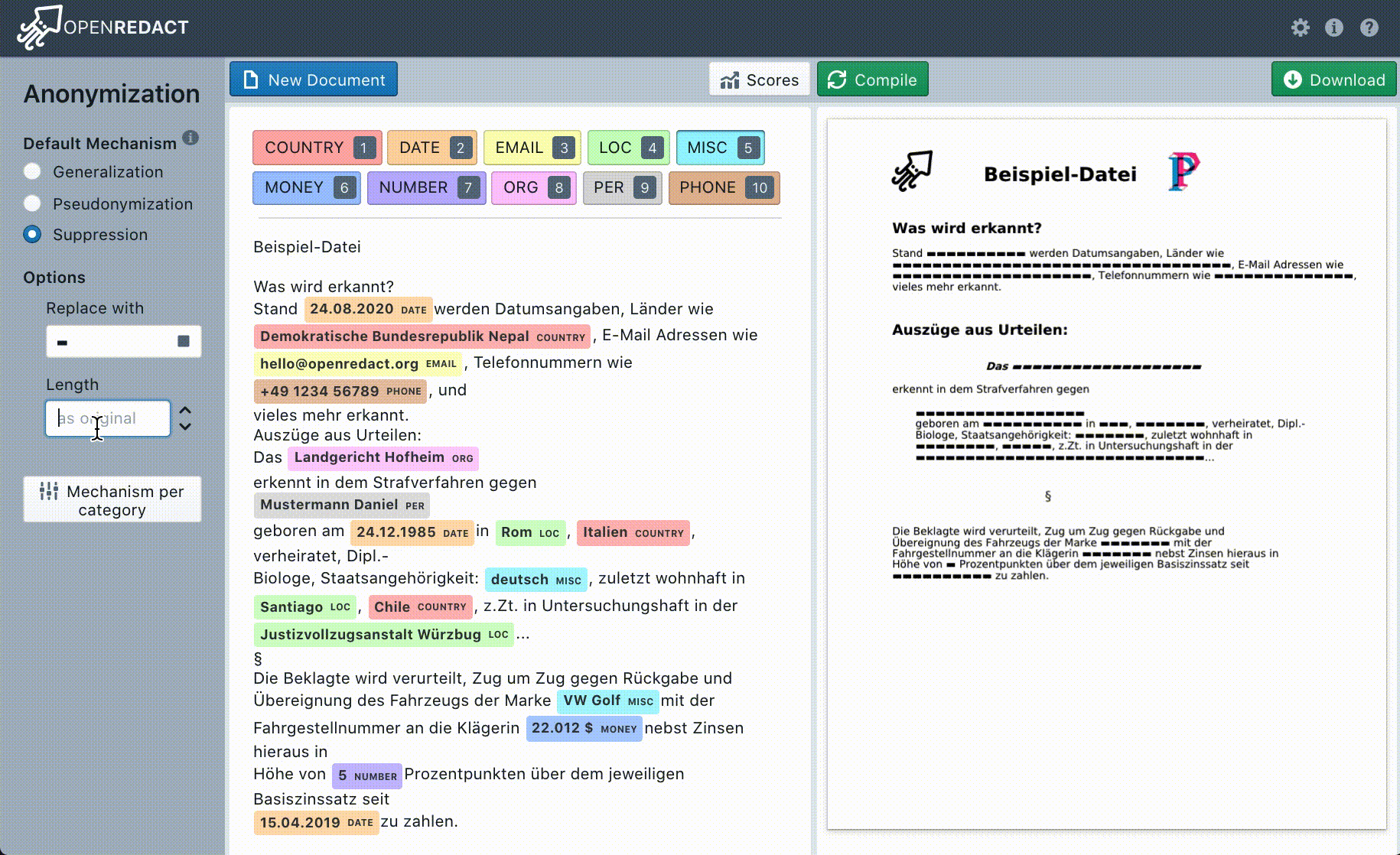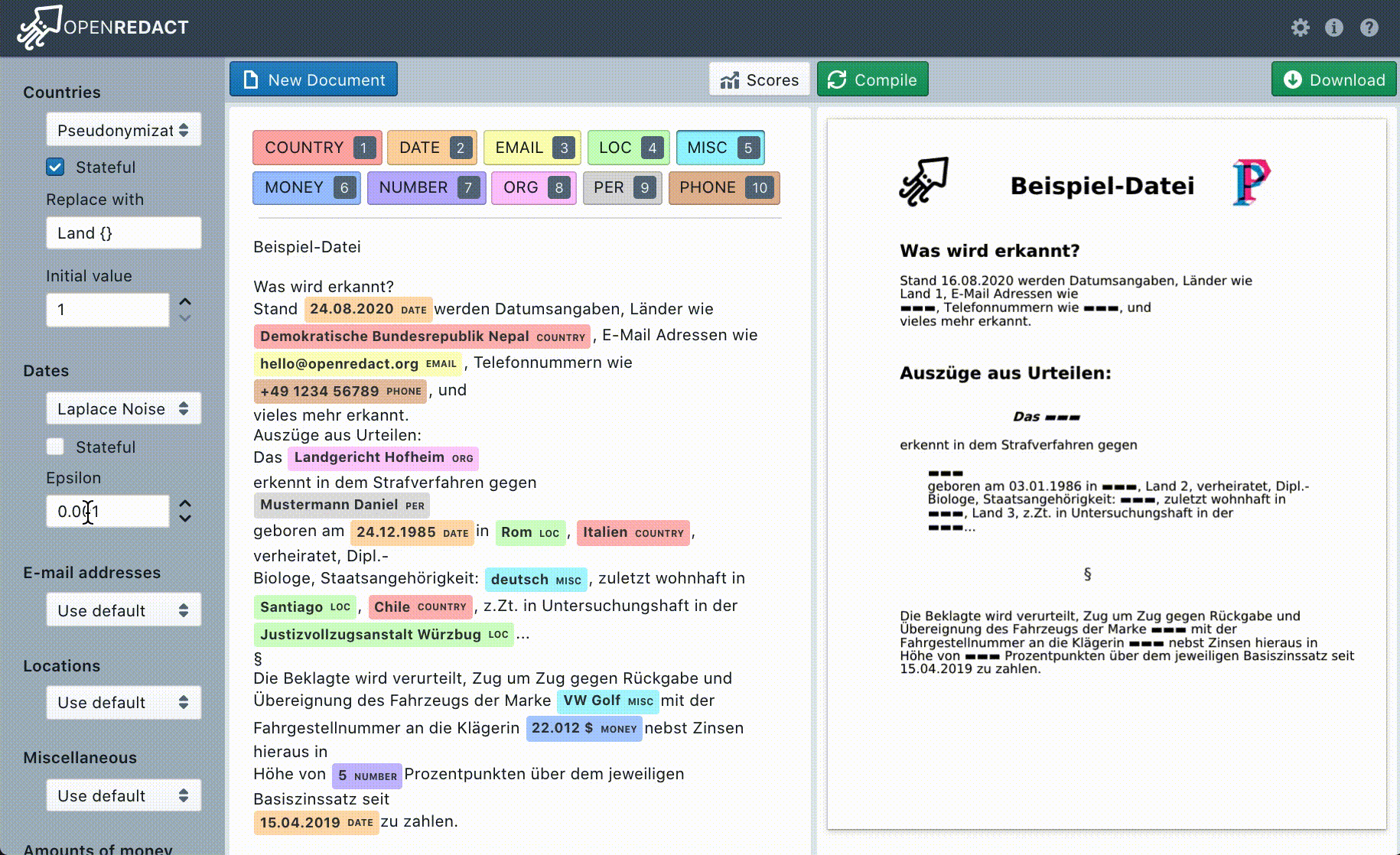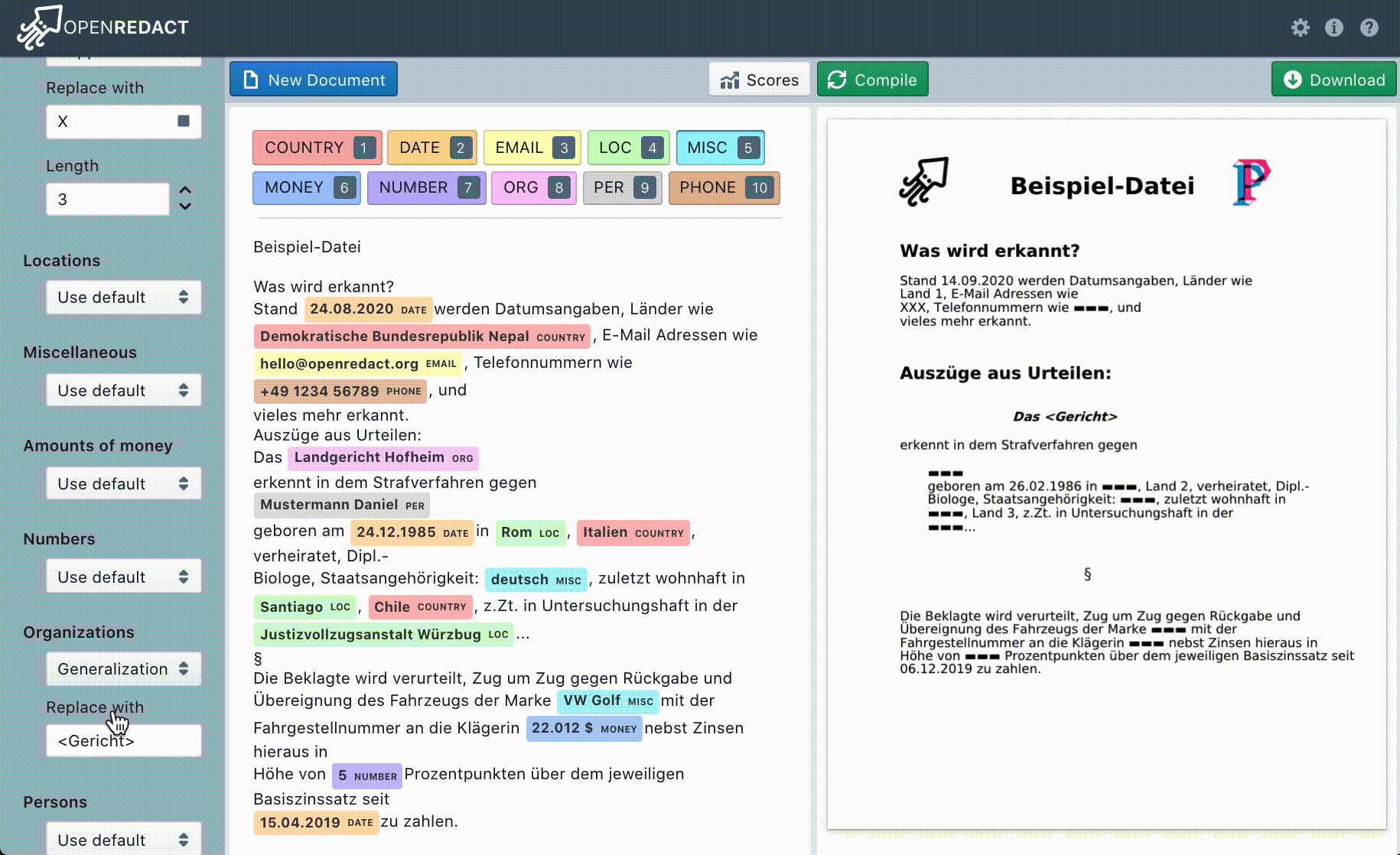
Beim Anonymisieren werden die zu schützenden Textinhalte durch einen Platzhalter ersetzt und damit die ursprünglichen Informationen unweigerlich zerstört. Die restlichen Methoden wie Pseudonymisieren und Differential Privacy zielen darauf ab, Teile der ursprünglichen Informationen zu erhalten und dennoch die persönlichen Daten zu schützen.
Beim Generalisieren wird ein Textbaustein durch die respektive Kategorie der Daten ersetzt. Generalisiert man beispielsweise den Namen “Hans”, so könnte das Ergebnis “männliche Person” oder auch einfach “Person” sein. Das Pseudonymisieren verfährt ähnlich, erlaubt jedoch noch die Unterscheidung zwischen unterschiedlichen Werten der gleichen Kategorie durch eine Nummerierung. Danach würde “Hans” zu “Person 1” und “Anna” zu “Person 2” werden.
Einen ganz anderen Ansatz verfolgen unsere beiden Methoden, welche auf Verrauschen setzen. Verrauschen bedeutet, dass die Werte zufällig durch andere Werte der gleichen Kategorie ersetzt werden – aus “Anna” könnte also “Hannah” werden.
Unsere beiden Methoden des Verrauschens basieren auf dem Ansatz der Differential Privacy. Differential Privacy ist eigentlich ein Ansatz, welcher für den Datenschutz in Datenbanken gedacht ist. Differential Privacy hat das Ziel statistische Auswertungen über die gesamte Datenbank zu ermöglichen und dennoch die Informationen jedes Einzelnen zu schützen. Zu diesem Zweck wird das Rauschen nach speziellen Wahrscheinlichkeitsverteilungen angewandt. Am einfachsten lässt sich dies anhand numerischer Werte illustrieren: aus dem Geburtsdatum 01.12.2001 kann z. B. 05.02.2002 werden oder aber auch 28.01.1902. Die Wahrscheinlichkeitsverteilung sorgt jedoch dafür, dass letzteres wesentlich unwahrscheinlicher ist als ersteres. Eben genau dadurch ist gewährleistet, dass statistische Aussagen noch möglich sind, da das verrauschte Datum mit hoher Wahrscheinlichkeit nah am Ursprungsdatum liegt. Gleichzeitig kann man sich jedoch nicht sicher sein, was das wirkliche Ursprungsdatum war und Betroffene haben sogenannte “plausible deniability”, d. h. Betroffene können immer glaubhaft machen, dass ein Datenpunkt nicht der eigene ist.
Bei allen Methoden muss man sich bewusst sein, dass Kontextinformationen genutzt werden können, um auf die ursprünglichen Daten zu schließen: Wird im Text “Lisa wohnt in der Sonnenallee 1” lediglich der Vorname getauscht, ist es recht einfach, über den Kontext wieder auf die ursprünglichen Informationen zu schließen. Daher ist immer eine manuelle Nachprüfung notwendig.
Unsere Anonymisierungsmethoden lassen sich abhängig von den persönlichen Daten einstellen, um dem Prinzip der Datensparsamkeit gerecht zu werden. Sollen für einen Datentyp z. B. noch statistische Auswertungen möglich sein, muss man auf eine Methode des Verrauschens zurückgreifen. Müssen keine personenbezogenen Daten bekannt sein, ist das Anonymisieren zumeist die beste Möglichkeit. Sollten zumindest noch die Zusammenhänge erkenntlich sein, kann das Pseudonymisieren die präferierte Technik sein.
Mehr Details über die Funktionsweise und Benutzung unserer Anonymizer Bibliothek sind in unserem Anonymizer Blogpost zu finden.
Fazit
Die Teilnahme am Prototype Fund hat es OpenRedact ermöglicht, die Idee von einem offenen teil-automatisierten Anonymisierungstool umzusetzen. Im Laufe der letzten sechs Monate hat OpenRedact technische und juristische Lösungen entwickelt, die helfen werden den Aufwand und die Kosten für die Veröffentlichung von Dokumenten als Open Data zu senken. Mit Hilfe unserer Web-App können PDFs und andere Dokumente von personenbezogenen Daten bereinigt werden. Bei der Entwicklung des Prototyps haben wir besonderen Wert auf die Nachnutzbarkeit gelegt. Alle Komponente sind eigenständig nutzbar, insbesondere der Anonymisierungsleitfaden soll auch über die Projektgrenzen hinweg eine juristische Diskussion zu Open Data und Datenschutz anstoßen. Darüber hinaus haben unsere Arbeiten gezeigt, dass beim Einsatz von OpenRedact branchenspezifische Anforderungen beachtet werden müssen. Aus diesem Grund haben wir Anpassungsmöglichkeiten besonders berücksichtigt. Beispielsweise könnten die statistischen Modelle der NERwhal-Komponente mit zusätzlichen Trainingsdaten an den genauen Anwendungsfall angepasst werden.
Wir zeigen mit unserem Prototypen die technischen Möglichkeiten von teil-automatisierter Anonymisierung und bieten eine Grundlage für die zukünftige Zusammenarbeit und Nutzung des öffentlichen Sektors.
Ein großer Dank für die Ermöglichung dieses Prototypen geht an das Prototype-Fund-Team und das BMBF. Weiterhin bedanken wir uns für die großartige Begleitung des Projektes durch den DLR Projektträger und Simply Secure.
- Website: https://openredact.org/
- Twitter: https://twitter.com/openredact1
- GitHub: https://github.com/openredact