
Zurück zur Startseite
pd3f: PDF zu Fließtext mit maschinellem Lernen
Wir extrahieren Fließtext aus PDFs.
Durch lange Wörter im Deutschen sind aus PDF extrahierte Texte mit Zeilenumbrüchen zerstückelt. pd3f rekonstruiert mithilfe von maschinellem Lernen den ursprünglichen Fließtext.

PDF zu Fließtext mit maschinellem Lernen
PDFs sind für Menschen gemacht und nicht für Maschinen (Computer). Das führt dazu, dass wir sie lesen können, aber Maschinen Probleme damit haben, Text zu extrahieren. Dies ist jedoch notwendig, um z. B. große Mengen von PDFs im Rahmen journalistischer Recherchen auszuwerten. Auch Personen mit Seheinschränkungen sind darauf angewiesen, dass Computer ihnen Texte vorlesen. Im Rahmen der bereits erfolgten oder geplanten Digitalisierung deutscher Behörden müssen zudem große Aktenbestände digitalisiert werden.
Text extrahieren mit pd3f
Im Rahmen der Prototype-Fund-Förderung von “DDD: Deutsche Dokumente Digitalisieren” ist die Software-Lösung pd3f entstanden, um “guten” Text aus PDF zu rekonstruieren -
“gut” bedeutet hier, dass der ursprüngliche Text ohne unnötige Zeilenumbrüche wiederhergestellt werden kann.
Aus dem zerstückelten Text im PDF wird somit wieder ein digitaler Fließtext.
Im Deutschen gibt es viele lange Wörter und deswegen die Besonderheit, dass Wörter am Zeilenende getrennt werden.
Bei einer üblichen Textextraktion werden getrennte Wörter jedoch nicht wieder zusammengefügt.
Damit kann das ursprüngliche Wort z. B. nicht mehr per Suche gefunden werden.
Auch weiterführende Anwendungen, wie z. B. die automatisierte Erkennung von Eigennamen (Named-Entity Recognition), werden erschwert.
Automatisierte Texterkennung
Texterkennung auf gescannten Dokumenten (Optical Character Recognition/OCR) erfolgt schon heute zufriedenstellend mit Open-Source-Lösungen. Es ist aber aufgrund des veralteten Portable Document Format (PDF) weiterhin schwierig, die Wörter aus einem PDF zu einem Text zusammenfassen. Das Format folgt der Idee des Druckens, weshalb Fließtext darin nicht als Text dargestellt wird. Stattdessen wird teilweise jeder einzelne Buchstabe als Zeichen kodiert und ihm eine Position (x- und y-Wert für Höhe und Breite) auf dem (virtuellen) Blatt Papier zugewiesen.
Um aus diesem Buchstabensalat nutzen bestehen Tools Heuristiken, um Buchstaben zu Wörter zuzusammen zu setzen.
Aus Wörtern müssen wieder ganze Zeilen und diese Zeilen anschließend zu Paragraphen zusammengefasst werden.
Das ist ohnehin eine schwierige Aufgabe, da es für den Satz eines Textes nahezu endlose Möglichkeiten gibt.
Das Open-Source-Tool Parsr des französischen Versicherungskonzerns Axa sorgt bereits für Besserung, denn es zerlegt relativ erfolgreich ein PDF in Zeilen und Absätze.
Das Tool ist wenige Monate vor Start der Projektförderung erschienen und erwies sich in der Projektphase als nützlich.
Unsere Software pd3f füttert zunächste das PDF in Parsr und nutzt die Ausgabe von Parsr, um darauf aufbauend guten Text wiederherzustellen.
Zeilenumbrüche entfernen
Worttrennung an Zeilenumbrüchen zu entfernen, ist eigentlich eine einfache Aufgabe: Alle Wörter mit einem “-“ am Zeilenende werden mit dem Wort auf der darauffolgenden Zeile zusammengefügt wie in diesem Beispiel.
… die Bedeutung der finan-
ziellen Interessen der Union …
Das Wort “finanziellen” entspricht dem ursprünglichen Text.
Es gibt aber auch “-“ am Zeilenenden, das nicht entfernt werden darf, weil es Bestandteil des Worter ist:
Auch andere EU-
Staaten, wie bspw. Polen, …
Um an dieser Stelle weiterzukommen, braucht es mehr Verständnis über die deutsche Sprache. Hier kommt maschinelles Lernen in Form von Sprachmodellen zum Einsatz.
Was sind Sprachmodelle? (Language Models)
Bei Sprachmodellen geht es darum, dass ein Computerprogramm neue Wörter auf der Basis bereits genutzter Wörter lernt. Zum Einsatz kommen Sprachmodelle z. B. auf Smartphones bei der Autovervollständigung. Sprachmodelle verinnerlichen die Charakteristiken der deutschen Sprache und können vorhersagen, welche Wörter oder Buchstaben wahrscheinlich als nächstes kommen. So kommt nach “Sehr geehrte” wahrscheinlich “Frau” als nächstes.
Solche Sprachmodelle operieren auf ganzen Wörtern oder auch nur auf Buchstaben (um nachfolgende Buchstaben zu erraten).
Texte reparieren mit dehyphen
Eine Unterkomponente von pd3f ist das Softwarepaket dehyphen, welches ebenfalls im Rahmen der Förderung entstand.
Es benutzt Sprachmodelle, um zu entscheiden ob ein “-“ am Zeilenende entfernt werden sollte oder nicht.
Die Grundidee ist dabei eine Berechnung darüber, welche die wahrscheinliche Möglichkeit ist, zwei Zeilen zu verbinden.
Auch andere EU-
Staaten, wie bspw. Polen, …
Bei diesem Beispiel kommt dehyphen zum richtigen Ergebnis: “EU-Staaten” ist korrekt, nicht “EUStaaten”.
dehyphen kann als Modul von anderen Software-Entwickler*innen einfach wiederverwendet werden.
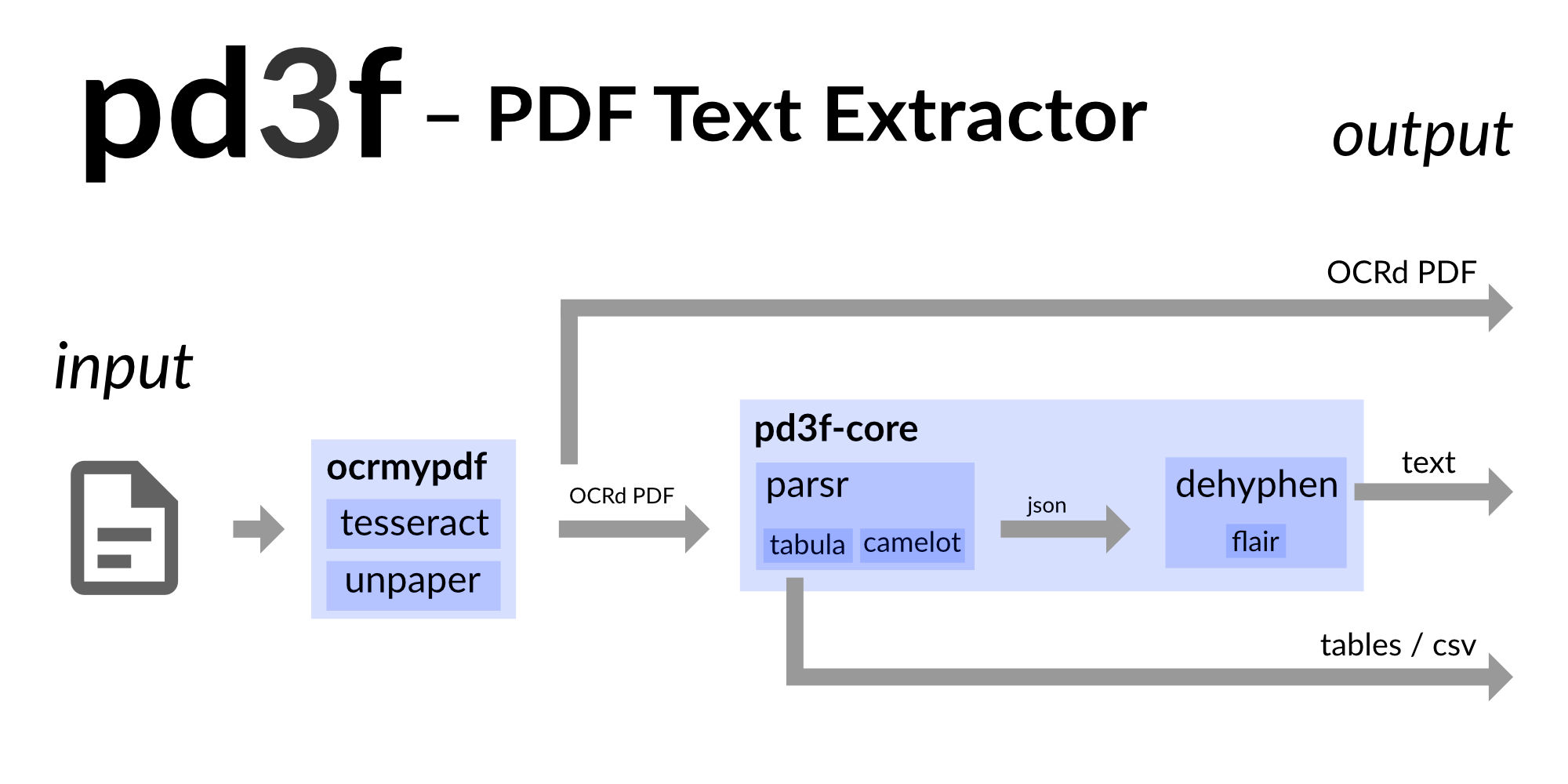
Datenverarbeitungs-Pipeline pd3f
Das Hauptergebnis der Förderung ist pd3f: Eine komplette Anwendung und eine Datenverarbeitungs-Pipeline für PDFs.
Mit ihrer Hilfe können (deutsche) Dokumente digitalisiert werden.
Auf einem gescannten Dokument wird der Text automatisiert gescannt, dann mithilfe von Parsr der Text in Wörter, Zeilen und Absätze unterteilt.
Anschließend wird mithilfe von dehyphen guter Text extrahiert.
Anbei eine schematische Auflistung der benutzten Komponenten.
Der Fokus liegt auf der deutschen Sprache, deren besonderes Charakteristikum lange Wörter sind, pd3f kann aber auch für andere Sprachen angewandt werden.
Es ist aktuell auch für Englisch, Spanisch und Französisch verfügbar.
Wer nach dieser kleinen Einführung mehr über pd3f erfahren möchte, dem sei die ausführliche Dokumentation zum Quellcode empfohlen.
Der Code wird online https://github.com/pd3f/pd3f stehen und weiter gepflegt.
Die Hauptfunktionalitäten von pd3f sind zusätzlich in einem eigenen Python-Paket https://github.com/pd3f/pd3f-core gebündelt, sodass auch hier eine einfach weitere Verwendung möglich ist.
Weitere Arbeit
Da Dokumente in so vielen unterschiedlichen Formen vorkommen, funktioniert pd3f noch nicht für alle PDFs.
Gerade bei schlecht gescannten PDFs ist der extrahierte Text zudem noch stark verbesserungsbedürftig.
Es ist unwahrscheinlich, dass pd3f jemals für alle PDFs funktionieren wird, doch es wird weiterhin gearbeitet, die Resultate, z. B. für mehrspaltige Dokumente, zu verbessern.
Was noch fehlt, ist eine systematische Evaluation der Textextrakte von pd3f.
Diese wird voraussichtlich im September 2020 erfolgen.
Ich danke dem Prototype Fund und dem DLR-Projektträger für die Betreuung des Projekts, Ame Elliott und Eileen Wagner von Simply Secure für das Coaching und dem BMBF für die finanzielle Förderung.
Website: https://pd3f.com
Twitter: https://twitter.com/pd3f_
GitHub: https://github.com/pd3f
von Johannes Filter
Webseite: https://johannesfilter.com
Twitter: https://twitter.com/fil_ter