
Zurück zur Startseite
Annotate & Chill
Wir zeigen, aus welchen Quellen Informationen stammen.
Seit einigen Jahren arbeiten Recherche-Teams verstärkt mit großen Dokumentensammlungen oder “Leaks”. Die Herausforderung ist immer gleich: Aus einem unstrukturierten Wust strukturierte Erkenntnisse zu generieren, sie zunächst mit Kolleg*innen und später mit der Öffentlichkeit zu teilen. Hier eine Übersicht über Herangehensweise, den aktuellen Stand sowie ein neues Puzzleteil in einer immer weiter wachsenden Werkzeugkiste.

Die Stecknadel im Heuhaufen wiederfinden
Seit einigen Jahren arbeiten Recherche-Teams verstärkt mit großen Dokumentensammlungen oder “Leaks”. Die Herausforderung ist immer gleich: Aus einem unstrukturierten Wust strukturierte Erkenntnisse zu generieren, sie zunächst mit Kolleg*innen und später mit der Öffentlichkeit zu teilen. Hier eine Übersicht über Herangehensweise, den aktuellen Stand sowie ein neues Puzzleteil in einer immer weiter wachsenden Werkzeugkiste.
Das Problem
Die Diskussion um “Vertrauen in die Medien” oder “alternative Fakten”, um nur zwei Schlagworte zu nennen, ist gerade in den vergangenen Monaten der weltweiten Corona-Pandemie wieder erneut entflammt. Doch schon länger sind Medien und damit ihre Rechercheur*innen, einem wachsenden Vertrauensanspruch seitens der Konsument*innen ausgesetzt – und das völlig zu Recht. Erkenntnisse sollen und müssen transparent und nachvollziehbar sein. Nur so entsteht Glaubwürdigkeit. Eine Möglichkeit, um diesem Anspruch gerecht zu werden, kann darin bestehen, originale Quellen, auf die sich Fakten und Aussagen stützen, ebenfalls zu veröffentlichen. Sofern es der Quellenschutz zulässt.
Damit das überhaupt möglich ist, müssen Recherche-Teams, egal ob in de Medien oder anderen Organisationen, auch intern einige Herausforderungen meistern: Wie generieren wir Erkenntnisse aus großen Dokumentensammlungen? Wie überführen wir diese in strukturierte Fakten? Wie stellen wir sicher, dass wir unsere Erkenntnisse bzw. ihre Quellen später wiederfinden – zum Beispiel für eine neue Recherche? Wie können wir kollaborativ aber möglichst sicher zusammenarbeiten? Wie können wir unsere eigenen, auf Dokumenten basierenden Recherchen, effizient fakt-checken?
Das Ziel
Neben vielen konzeptionellen Überlegungen kann auch technische Infrastruktur helfen, diese Ziele zu erreichen. Idealerweise funktioniert das so: Rechercheur*innen durchforsten ihr Originalmaterial und extrahieren Erkenntnisse, die ihr konkretes Thema betreffen. Diese Informationen haben eine bestimmte, vorher definierte Datenstruktur, sodass sie von anderen Systemen, z. B. Suchdatenbanken, weiter verwertet werden können. Die Beteiligten können diese Erkenntnisse mit Kolleg*innen teilen und gemeinsam daran arbeiten – selbstverständlich unter den für das spezifische Projekt geltenden Sicherheitsvorkehrungen. Am Ende einer Recherche können Fakten und ihre Quellen (sofern möglich) verlinkt werden, mit einer eindeutigen URL, die sich nicht ändert und eindeutig auf die Quelle einer Aussage verweist.
Die Ausgangslage
Natürlich haben sich in den vergangenen Jahren einige Software-Projekte diesem Thema gewidmet. Um Dokumentenberge zu knacken, lesbar zu machen und zu durchsuchen, haben sich “Datashare” vom International Consortium of Investigative Journalists (ICIJ) und insbesondere “Aleph” vom Organized Crime and Corruption Project (OCCRP) etabliert. Beides sind Open-Source-Lösungen, die auch von anderen Newsrooms und Organisationen eingesetzt und mitentwickelt werden. Mit dem “follow the money”-Werkzeugkasten als Teil des Aleph-Systems ist es möglich, die unstrukturierte, reale Welt in maschineller Form so zu modellieren, sodass sie auch ein Computer verstehen kann.
Eine Aussage, belegt durch eine bestimmte Stelle innerhalb eines Dokuments, kann technisch gesehen als “Annotation” abgebildet werden. Auch darüber haben sich bereits viele Entwickler*innen den Kopf zerbrochen: So ermöglicht das Projekt “hypothes.is” mehr oder weniger das komplette Internet zu annotieren, also beliebige Stellen von Webseiten mit Kommentaren zu versehen. Die Annotationen landen auf dem hypothes.is-Server und sind entweder privat sichtbar oder können mit User-Gruppen oder der Öffentlichkeit geteilt werden.
Die Nische
Die Umsetzung für den beschriebenen Anwendungsfall lautet also im weitesten Sinne “Annotationen”. Trotzdem gab es für eine bestimmte Konstellation von Anforderungen bisher keine einfache technische Lösung – und dafür wurde im Rahmen der Förderung durch den Prototype Fund “Annotate & chill” gebaut. Diese Software geht von drei Nutzungsszenarien aus: Erstens, Annotierung kann (muss aber nicht) lokal und offline stattfinden und wird nicht (kann aber) in einer Cloud gespeichert. Zweitens, Annotierungen sind getrennt von den Quelldokumenten und können unabhängig davon verbreitet werden. Und drittens gibt es kein festgelegtes Format für Annotationen, es kann je nach Anwendungsfall und verwendeter Dritt-Software flexibel angepasst werden.
Die Umsetzung
Wer schon einmal einen Film auf Youtube oder in einem Player geschaut hat und auf der Suche nach passenden Untertiteln war, kennt das Prinzip: Es lässt sich meist irgendwo im Internet eine “.srt”-Datei finden, die in einem definierten Format die Untertitel für die gewünschte Sprache sowie Zeitstempel, wann diese eingeblendet werden sollen, enthält. Diese Datei importiert man in Youtube oder den lokalen Player, und schon werden die vorher fehlenden Untertitel, die nicht in der originalen Filmdatei enthalten waren, eingeblendet.
Genau so funktioniert “Annotate & chill” – die Annotationen lassen sich als Datei exportieren und woanders wieder mit der Quelldatei verbinden und anzeigen. In besonders sicherheitssensiblen Recherche-Szenarios können so die Annotationen getrennt von den Dokumenten unter Kolleg*innen geteilt werden. So kann ein*e Rechercheur*in beispielsweise eine verschlüsselte Datei mit Anmerkungen an ein*e Kolleg*in schicken, die das Originaldokument ebenfalls besitzt oder auf anderem Wege erhält. Annotationen können über das Interface importiert, bearbeitet und wieder exportiert werden.
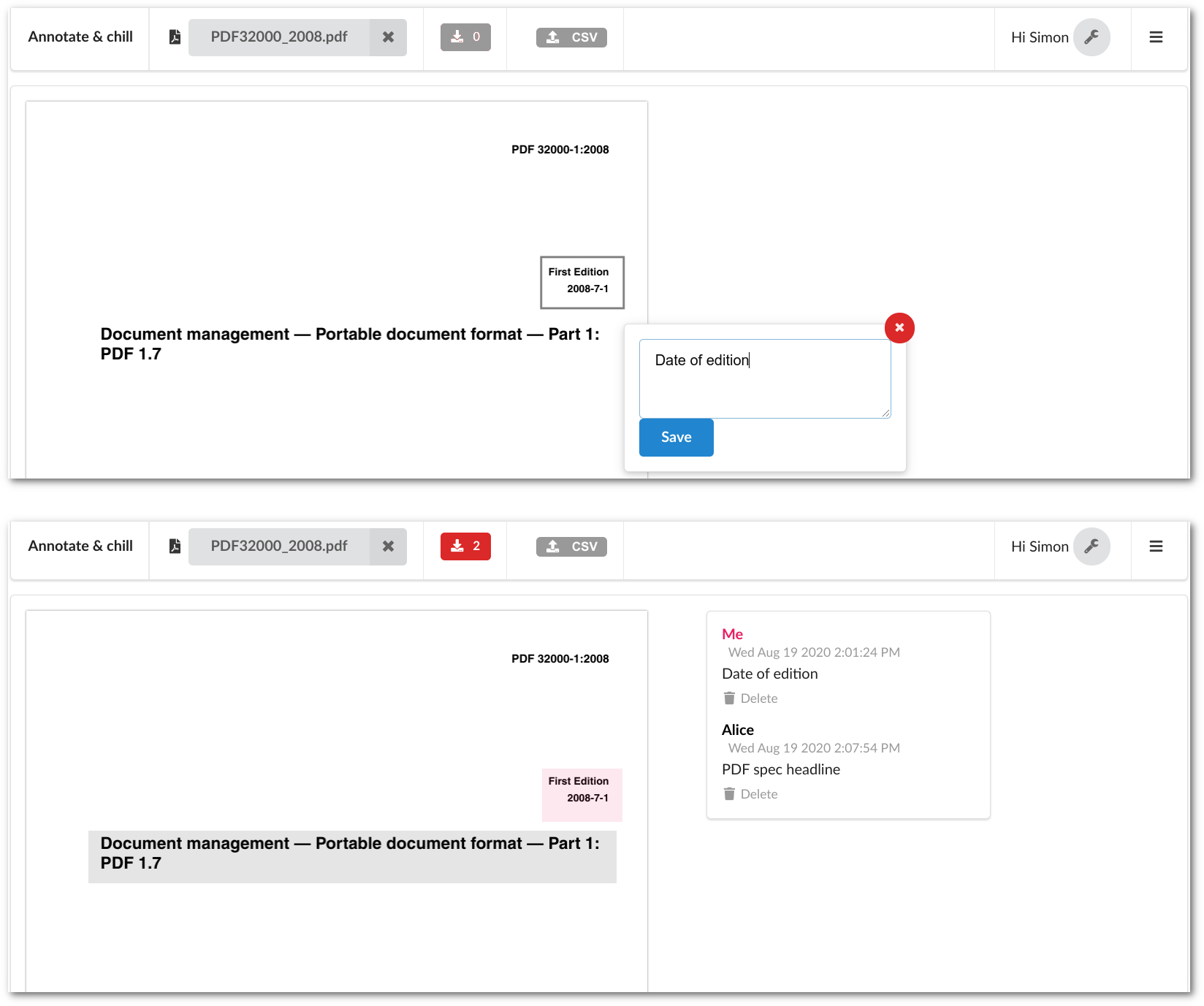
Zusätzlich gibt es auch eine Server-Anwendung, die kollaboratives Arbeiten in der Cloud ermöglicht – selbstverständlich self-hosted, um an die jeweiligen Sicherheitsansprüche eines Projekts angepasst zu werden (z. B. Erreichbarkeit nur über einen VPN-Zugang). Mittels dieser Plattform werden Annotationen mit eindeutigen URLs versehen und können der Allgemeinheit zugänglich gemacht werden. Eine Datenbank hält vor, an welchen öffentlichen Orten im Netz die Quelldokumente verfügbar sind und verlinkt dorthin.
Die Herausforderungen
Die technischen Stolpersteine an diesem “losgelösten” Konzept werden schnell sichtbar: Wie kann der exakte Ort innerhalb einer Datei, auf den sich eine Annotation bezieht, definiert werden? Wenn die Dokumente dezentral oder nur auf den lokalen Computern der Teammitglieder eines Recherche-Teams existieren, hilft beispielsweise eine URL als eindeutige Zuweisung nicht weiter. Hier kommt eine andere, schon lange etablierte Methode zum Tragen: Die sogenannte “Prüfsumme”. Aus jeder Datei lässt sich diese Zeichenkette erstellen, die als eindeutige ID funktioniert. So können Annotationen einer Datei immer zugeordnet werden, egal ob das Dokument sich im einen Fall auf dem Laptop einer Person oder in einem anderen Fall in einer Online-Datenbank befindet.
Wenn Quellen (wie z. B. PDF-Dokumente) aus mehreren Seiten bestehen, ist das eine weitere Information für den Ort einer Annotation. Auf einer Seite (oder auf einem Bild) wird die Stelle der Annotation näherungsweise als ein Rechteck angegeben, dass die Rechercheur*innen auf die Datei zeichnen. Aufgrund verschiedener Überlegungen wurde darauf verzichtet, genaue Textauswahl als Identifizierung zu nutzen – die ist nur in einigen Dokumententypen enthalten und kann auch bei einem scheinbar gleichen Dokument je nach Qualität der Texterkennung unterschiedlich sein.
Apropos “scheinbar gleich”: Ein weiteres Feature der Server-Version von “Annotate & chill” ermöglicht, verschiedene Prüfsummen für Dokumente zu hinterlegen. Denn was für das menschliche Auge das gleiche Dokument ist, kann für den Computer aufgrund technischer Gründe (Konvertierung, verschiedene Texterkennung via OCR, …) aufgrund anderer Prüfsummen unterschiedlich sein. Doch so kann sichergestellt werden, dass zum “Koalitionsvertrag 2021 (Langversion)” immer die richtigen Annotationen zugewiesen werden können, auch wenn es – technisch gesehen – verschiedene Versionen des Dokuments gibt.
So ergibt sich aus Prüfsumme, Seitenzahl und Rechteck der eindeutige Ort, auf den sich eine Annotation bezieht. Diese Information wird samt einem “body”, der die eigentliche Annotation enthält, lokal oder, wenn gewünscht, auf einem Server gespeichert. Das “body”-Feld einer Annotation ist völlig frei befüllbar, es kann einfachen Text oder eine komplexere Datenstruktur (via JSON) enthalten – je nach Anwendungsfall.
Beispiel für den eindeutigen “Ort” einer Annotation:
<checksum>:<page>:rct:<x1>,<y1>,<x2>,<y2>
60b73bd4e7c412cbbdb81cc87254a595:2:rct:10,75,83,79
Die Zukunft
“Annotate & chill” ist natürlich nicht fertig geworden, sondern lediglich ein Prototyp. Bisher können PDF-Dokumente verarbeitet werden, doch das Interface soll in Zukunft mit mehr Dateiformaten umgehen können. Außerdem soll das Kernstück, der Reader mit der Engine zum Erstellen und Rendern von Annotationen, als unabhängige Software (als npm package) angeboten werden, sodass er in bestehende Plattformen integriert werden kann. Wie schon erläutert wurde kein Standard zum technischen Aussehen einer Annotation implementiert – Entwickler*innen können selbst definieren und implementieren, ob eine Annotation ein einfacher Kommentar oder ein komplexes Datenobjekt sein soll und in welche Systeme sie integriert oder abgespeichert werden kann.
Der “Annotate & chill”-Client ist eine standalone Javascript-App, die im Browser funktioniert und keine weiteren Abhängigkeiten braucht. Deshalb soll sie mit Hilfe des “electron”-Frameworks als eigene App für Windows, Mac und Linux gebaut und angeboten werden, sodass auch Rechercheur*innen ohne technisches Know-How sie auf ihrem Gerät einfach nutzen können.
Eine einfache Demo ist unter https://demo.annotate.cool zu erreichen. Hier können PDF-Dokumente annotiert und die Annotationen im CSV-Format exportiert (und wieder importiert) werden. Auch wenn die Anwendung auf einem Server läuft, funktioniert sie technisch gesehen nur im Browser (Client) der Nutzer*innen; die PDF-Dokumente sowie die Annotationen werden niemals irgendwohin hochgeladen sondern nur lokal gespeichert.
Das Fazit
Das Feld rund um Dokumentenanalyse, v. a. für PDF, ist riesig und es gibt viele kleinere und größere, teilweise sehr erfolgreiche Open-Source-Projekte. In der Praxis zeigt sich, dass die großen “All-in-One”-Lösungen viele Anwendungsfälle abdecken können – aber nicht alle. Anstatt ein weiteres großes, generalistisches Tool zu bauen, ist es heute sinnvoller, spezifische Ergänzungen zu entwickeln, die an bestehende Projekte andocken können. Meist ist es sinnvoller, für ein Projekt oder eine Recherche-Organisation aus verschiedenen Angeboten, die alle technisch miteinander kommunizieren können, einen eigenen Stack zusammenzubauen. “Annotate & Chill” hat nicht den Anspruch einer Komplettlösung für leak-basierte, kollaborative Recherchen, sondern will möglichst flexibel bestehende Setups um das konkrete Feature dezentrales, sicheres Annotieren, erweitern.
Dieses Projekt wäre ohne die Förderung im Rahmen des Prototype Funds der Open Knowledge Foundation und der finanziellen Unterstützung des BMBF nicht realisiert worden. Darüber hinaus geht Dank an Simon Höher von zero360, der einen übergroßen Plan in ein konkretes Produkt gegossen hat, an Friedrich Lindenberg und Johannes Filter für Support und inspirierenden Austausch über (fast) alles, was mit Erkenntnisgewinn aus Dokumenten zu tun hat, und an Marie & Tasmo vom Projektteam für die individuelle Betreuung über die vergangenen sechs Monate in diesem etwas seltsamen Jahr 2020.