
Zurück zur Startseite
Dystonse - Wahrscheinlichkeitsbasierte ÖPNV-Routenplanung
Wir steigern das Vertrauen in den ÖPNV.
Der erweiterte Abfahrtsmonitor macht die Wahrscheinlichkeitsverteilung von Ankunfts- und Abfahrtszeiten im ÖPNV sichtbar und berechnet die Chance für erfolgreiche Umstiege.

Wir steigern das Vertrauen in den ÖPNV
Wann kommt endlich die Straßenbahn? Laut Fahrplan sollte sie schon längst da sein, aber sie ist noch nicht zu sehen. So langsam wirst du nervös – falls sie jetzt noch mehr als drei Minuten braucht, dann würdest du lieber den Bus nehmen, den du am Bussteig nebenan schon einfahren siehst. Wobei… der braucht halt eigentlich eh immer länger, du müsstest unterwegs umsteigen und der Umstieg ist dann auch oft ziemlich knapp. Also doch lieber weiter auf die Straßenbahn warten?
Eine nervige Situation, die im Moment noch ziemlich oft vorkommt. Und wenn du mal in einer anderen Stadt unterwegs bist, hast du dort nicht mal dieses Gefühl dafür, welche Linien meistens pünktlich sind und welche nicht. Mit etwas Glück zeigt dir ein Abfahrtsmonitor die aktuellen Verspätungen an, aber das sagt dir auch nichts darüber, wie diese sich während der Fahrt wohl entwickeln werden und wie wahrscheinlich es ist, dass du deinen Umstieg schaffst.
Warum kann mir nicht einfach eine Software diese Entscheidung abnehmen?
Uns geht es selbst oft so – und deswegen ist die Idee zu Dystonse entstanden. Wir sind davon überzeugt, dass Software für ÖPNV-Routenplanung nicht mit einfachen, absoluten Zeiten arbeiten sollte, sondern mit einer Verteilung von Wahrscheinlichkeiten.
Unser Ziel – für dessen Erreichung wir uns beim Prototype Fund beworben haben – ist eine vollständige Routenauskunft von A nach B, die schon während der Suche Verspätungen, Prognosen und Wahrscheinlichkeiten einbezieht. Bisher gab es das so noch nicht. Dass es prinzipiell möglich wäre, haben wir schon mit unserem ersten Prototypen von 2019 gezeigt, der damals so aussah:
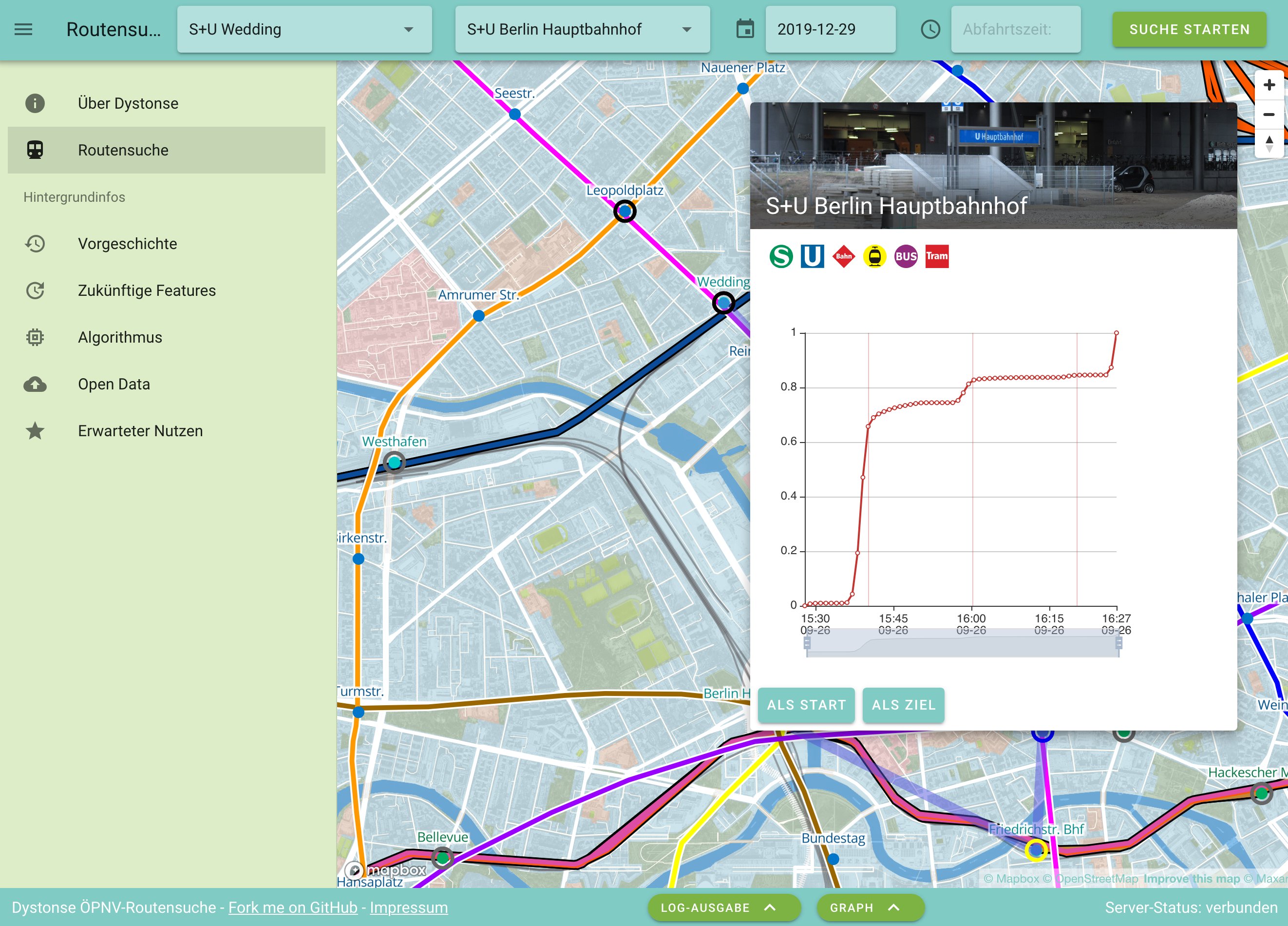
Den Prototypen haben wir damals innerhalb weniger Tage entwickelt – entsprechend unvollständig und fehlerhaft ist er auch. Außerdem sind die Daten, auf denen das Verspätungsmodell dort basiert, eine extreme Vereinfachung, die in der Realität nicht sehr nützlich ist.
Um die Routenauskunft diesmal verlässlich, realistisch und effizient umzusetzen, mussten wir nochmal bei Null anfangen und eine Menge Vorarbeit bei der Datensammlung und -aufbereitung leisten – mehr dazu folgt weiter unten. Die neue Version unserer Routensuche ist daher noch nicht fertig – wohl aber ein Vorgeschmack darauf.
Pünktlich zur Demo Week präsentieren wir unseren erweiterten Abfahrtsmonitor. Anders als die leuchtenden Anzeigen, die über manch einer Haltestelle hängen, zeigt er dir nicht nur die Abfahrten an deiner Start-Haltestelle an, sondern mit einem Klick auch den weiteren Verlauf der Linie und wie sich ihre Pünktlichkeit voraussichtlich entwickeln wird. Von da aus kannst du den Halt auswählen, an dem du aus- oder umsteigst, und Klick für Klick selbst deine Route zusammenstellen. Der Monitor zeigt dir jeweils an, wann du ungefähr ankommen wirst und wie wahrscheinlich die Umstiege sind.

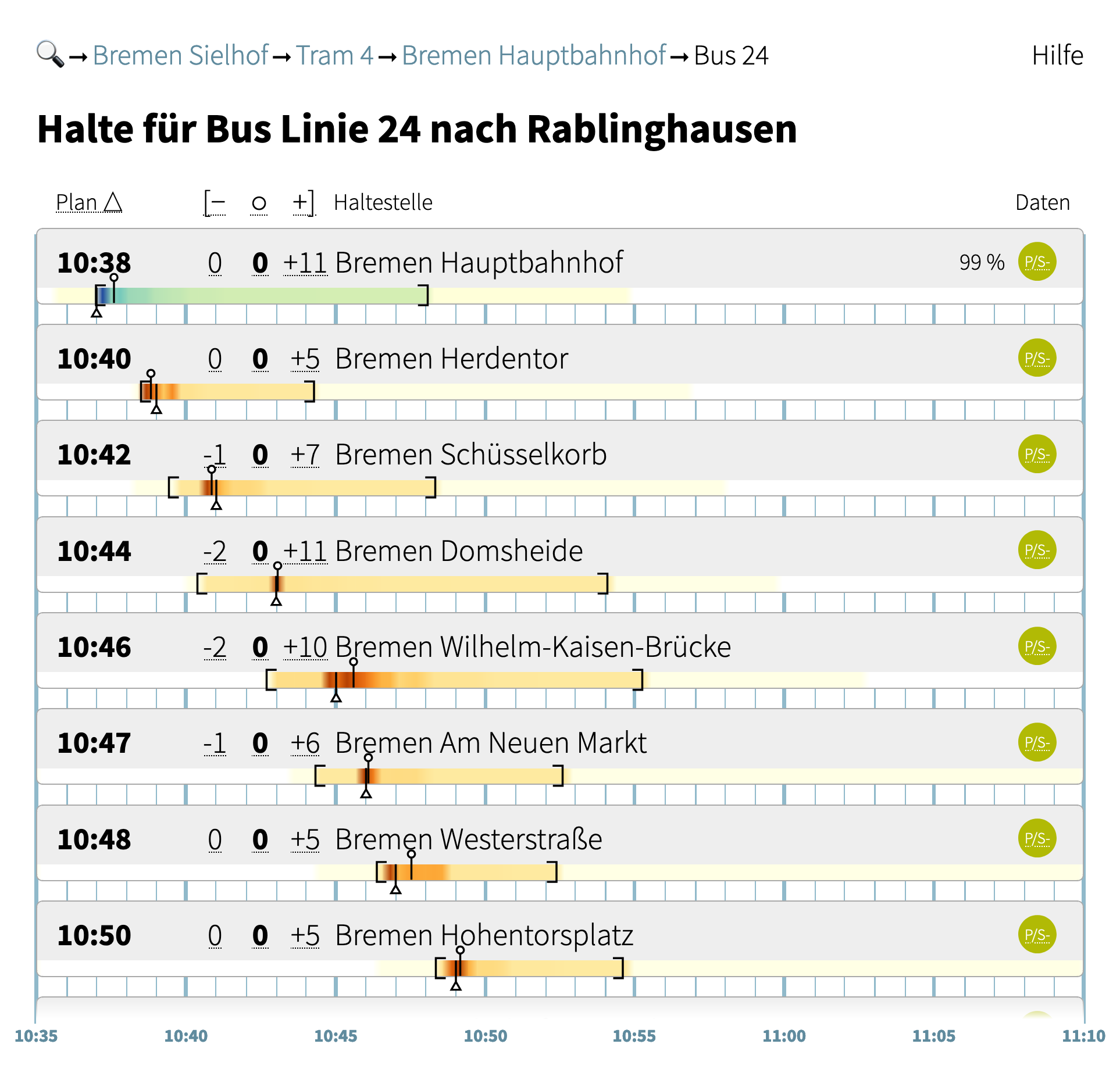
Hier kannst du den erweiterten Abfahrtsmonitor für den Verkehrsverbund Bremen/Niedersachsen gleich ausprobieren. Gib den Namen einer Haltestelle ein und klicke dann auf “Abfahrten anzeigen”:
(falls über dieser Zeile keine Suchmaske angezeigt wird, kannst du auch den Monitor direkt aufrufen)
Erweiterter Abfahrtsmonitor vs automatische Routensuche
Letztlich wollen wir alle wichtigen Infos in einer Anwendung zusammen bringen:
- Die Umsteigemöglichkeiten im Liniennetz
- Die Abfahrtszeiten laut Fahrplan
- Die aktuellen Echtzeit-Daten von einzelnen Fahrzeugen
- Und eben diese Intuition, die man als Mensch nur durch viel Erfahrung entwickeln kann. Wir nennen sie das Verspätungsmodell, also das Wissen darüber, welche Linien dazu neigen, besonders pünktlich oder unpünktlich zu sein, wo sie ihre Verspätung wieder aufholen etc.
Klassische Routensuchen und Abfahrtsmonitore berücksichtigen diese Infos teilweise gar nicht oder nur eingeschränkt:
| Liniennetz | Fahrplanzeiten | Aktuelle Echtzeitdaten | Verspätungsmodell | |
|---|---|---|---|---|
| Klassischer Monitor | Nein | Ja | Ja | Teils |
| Klassische Routensuche | Ja | Ja | Teils | Teils |
| Dystonse Monitor | Teils | Ja | Ja | Ja |
| Dystonse Routensuche | Ja | Ja | Ja | Ja |
Unser erweiterter Abfahrtsmonitor verwendet zwar alles davon – aber die Auswahl, welcher Umstieg nun der bessere ist, musst du hier im Gegensatz zur Routensuche noch selbst treffen. Mit der Visualisierung der Wahrscheinlichkeiten geben wir dir dazu möglichst viel Info an die Hand, um diese Entscheidung besser fundiert zu treffen.
In der Zeit nach der Demo Week werden wir die automatische Routensuche weiterentwickeln. Sie basiert auf der gleichen Technik und Datenbasis wie der erweiterte Abfahrtsmonitor, aber präsentiert dir nicht nur Informationen, sondern erstellt daraus automatisch die beste(n) Reisemöglichkeit(en). Natürlich wird es dazu eine große Ankündigung (z. B. auf Twitter) und noch den einen oder anderen Blogpost geben.
Was alles dahinter “stackt”
Der Abfahrtsmonitor und später die Routensuche sind nur der kleine Teil von Dystonse, der für alle Nutzer*innen sichtbar ist – der größte Teil des Dystonse-Software-Stacks bleibt “hinter den Kulissen”: Hier werden die Daten gesammelt, die wir für das Verspätungsmodell brauchen und das Modell wird berechnet.
Unser zentrales Datenformat: Wahrscheinlichkeits-Kurven
Wie so ein Verspätungsmodell aussieht, haben wir schon einmal ausführlich in unserem Blogpost “Um die Kurve gedacht” erklärt. Kurz gesagt: die Verteilung der Abfahrts- und Ankunftszeiten wird in Form von Kurven zusammengefasst, in denen jeder Zeit eine Wahrscheinlichkeit zugeordnet ist, wie häufig diese Zeit tatsächlich zutrifft.
Bei den Linien, von denen wir viele Echtzeitdaten aufgezeichnet haben, können wir nicht nur eine Kurve für jede Haltestelle berechnen, sondern auch die Abhängigkeit zwischen verschiedenen Haltestellen und den Einfluss vorheriger Verzögerungen. Also z. B. “wenn diese Straßenbahn an Haltestelle Nr. 20 mit 220 Sekunden Verspätung abfährt, wie verteilt sich dann die Ankunftszeit an Haltestelle Nr. 45”. Das sieht dann so aus:

Wer genauer wissen will, wie diese Grafik zu lesen ist, findet alle Infos dazu in unserem Blogpost.
Im Idealfall ist diese Kurve sogar noch nach der Tageszeit aufgeschlüsselt. Bei den Linien, für die wir weniger Echtzeitdaten gesammelt haben, sind die Kurven etwas weniger genau, damit die Datengrundlage nicht zu klein ist. Dann wird zum Beispiel die Tageszeit nicht berücksichtigt, oder es werden nicht nur Daten einer bestimmten Straßenbahnlinie genutzt, sondern alle Straßenbahnen zusammengefasst.
Datensammlung
Um diese Kurven berechnen zu können, brauchen wir natürlich erstmal eine Menge Daten. Davon gibt es zwei Sorten: Fahrpläne und Echtzeit-Updates.
Fahrpläne sind prinzipiell leicht verfügbar, und zwar seit Anfang 2020 für ganz Deutschland als Open Data. Über die Schwierigkeit, passende Echtzeitdaten zu bekommen und diese dann auch zu verwenden, haben wir in den ersten Wochen unserer Förderzeit bereits einen eigenen Blogpost geschrieben.
Zum Glück haben wir mit dem VBN einen Anbieter gefunden, der selbst nicht nur Echtzeit-Updates mit einer echten Open-Data-Lizenz, sondern auch die Fahrpläne mit den passenden IDs zur Verfügung stellt.
Der erste Teil unseres Software-Stacks sind also zwei collect-Skripte, die regelmäßig die Fahrplan- und Echtzeitdaten aus den VBN-Quellen herunterladen. Danach werden die für unsere Anwendung relevanten Daten von der import-Komponente zusammengefügt und in einer Datenbank gespeichert – diese ist deutlich schneller durchsuchbar als die Rohdaten.
Analysen
Sobald wir genügend Echtzeit-Updates gesammelt und mit dem richtigen Fahrplan verknüpft haben, können wir mit den Analysen beginnen. Dieser analyse-Schritt erzeugt das Verspätungsmodell (also die Kurven, die oben schon beschrieben wurden) je nach vorhandener Datenmenge so spezifisch wie möglich, so allgemein wie nötig.
Prognosen
Um diese Analysen dann auch nutzen zu können, ordnen wir jeder zukünftigen Fahrt (im aktuellen Testbetrieb reicht unser Monitor bis ca. eine Woche in die Zukunft) die passenden Kurven zu. So lange im Voraus können wir natürlich nur sehr allgemeine Vorhersagen treffen. Sobald Echtzeitdaten zu einem Fahrzeug eintreffen, aktualisieren wir damit laufend all seine Prognosen.
Diese werden dann z. B. vom Abfahrtsmonitor (und später von der Routensuche) direkt für einen bestimmten Zeitraum aus der Datenbank abgerufen.
Im Prinzip ist die Berechnung dieser Prognosen ein eigener predict-Schritt in der Datenverarbeitung, wie er im nachfolgenden Diagramm auch zu sehen ist. In Wirklichkeit finden diese Berechnungen bei uns schon im import-Schritt statt, so dass jede Echtzeit-Datei nur einmal verarbeitet wird.

Bei collect handelt es sich um ein paar Shell-Skripte. Die Komponenten import, analyse, predict und auch monitor sind in der Sprache Rust geschrieben und sind Module innerhalb unseres Universalwerkzeugs dystonse-gtfs-data (zum Code). Sie haben also alle die selbe Codebasis, aber laufen als eigenständige Prozesse. Außerdem muss eine MySQL-Datenbank laufen, auf welche die anderen Komponenten zugreifen, und ein gemeinsam genutztes Verzeichnis für die Dateiablage vorhanden sein. Zusammen mit phpMyAdmin, das wir zur Pflege der Datenbank verwenden, erreicht der Software-Stack also einiges an Komplexität.
Automatisierung und einfache Installation
Um die Installation des ganzen Software-Stacks möglichst einfach zu gestalten, haben wir die Abläufe mit Hilfe von Docker und Docker Compose automatisiert.
Dabei definieren Konfigurationsdateien, welche Komponenten gebaut und gestartet werden müssen und wie diese miteinander interagieren. Andere Dateien beschreiben jeweils die Konfiguration einer einzelnen Komponente. Mit wenigen Änderungen in einer Konfigurationsdatei könnten wir so z. B. weitere Datenquellen hinzufügen und die Installation auf einem neuen Server braucht nur noch wenig Handarbeit. Außerdem können wir dadurch die einzelnen Komponenten einfach getrennt voneinander updaten, debuggen und überwachen.
Erfahrungen und Ausblick
Wir haben nun schon fast ein halbes Jahr Förderzeit hinter uns, in der wir sowohl ungeplante Schwierigkeiten als auch überraschende Erfolge erlebt und vor allem viel gelernt haben. Vom Lernen einer wunderbaren neuen Programmiersprache über Abenteuer mit Datenbankindizes über Gigabytes von Echtzeitdaten gab es eine Menge Herausforderungen. Am Ende des Tages (d. h. oft auch erst in den frühen Morgenstunden) macht es einfach überglücklich, zu sehen, wie tausende Datensätze innerhalb von Sekunden durch unsere Softwarekomponenten fließen und in der Datenbank landen. Oder auch, dass der heimische Verkehrsbetrieb seit Kurzem auch Echtzeitdaten liefert – sogar für den Bus, der quasi Zuhause vorbei fährt.
Bis dahin war es aber auch ein langer Weg. So haben z. B. die Vorbereitung der Datensammlung, das Einrichten der Datenbank und die ersten Analysen viel länger gebraucht, als wir vermutet hatten – bei so großen Datenmengen ist es eben manchmal doch nötig, schon frühzeitig viel Aufwand in Performance-Optimierung zu stecken.
Und natürlich hat die Covid-19-Pandemie auch für uns einiges durcheinander gewirbelt. Anders als die meisten geförderten Projekte hatten wir immerhin den Luxus, sowieso im gemeinsamen Home Office Seite an Seite zu arbeiten.
Der ganze Themenbereich “ÖPNV” erscheint in diesen Zeiten generell in einem ganz anderen Licht: Fahrgäste sorgen sich gar nicht mehr so sehr darum, ob der Bus zu spät kommt, sondern eher um die Ansteckungsgefahr, und Anreize für mehr ÖPNV-Nutzung scheinen gerade sehr deplatziert. Das erschwert auch User-Befragungen, die wir daher aufgeschoben haben.
Aber die Pandemie geht hoffentlich bald vorbei und Vertrauen in den ÖPNV wird noch lange gebraucht, um Mobilität in Zeiten des Klimawandels zu ermöglichen. Also bleiben wir dran und entwickeln die geplante Routensuche auch nach dem Ende der Förderung noch weiter.
Die Umstellung vom Demo Day in Berlin zur Demo Week im Internet hat gegen Ende auch noch für zusätzliche Zeitknappheit gesorgt. Aber wir sind flexibel und ganz im Sinne des Prototype-Fund-Learnings „Brauchst du dieses Feature wirklich?“ haben wir – mit Hilfe eines geförderten Coachings – ein neues Konzept für die Präsentation in Form des erweiterten Abfahrtsmonitors statt der Routensuche erarbeitet.
Wir freuen uns sehr, dass wir in der Förderrunde 7 dabei sein durften. Danke an das Prototype-Fund-Team für die gute Betreuung, und an das BMBF und das DLR dafür, dass sie dieses Projekt möglich gemacht haben!
Außerdem haben wir während der Förderzeit eine aktive Community gefunden – nicht nur innerhalb der Projekte in Runde 7, sondern auch in der großen “Nerd-Bubble” zu unserem Themengebiet.
Ein Dank geht hier auch an den Verkehrsverbund Bremen/Niedersachsen, der unser Projekt so begeistert aufgenommen hat. Wir freuen uns, wenn sich andere Verkehrsverbünde davon inspirieren lassen und in Zukunft offen für Open-Data-Anwendungen sind – und mit diesem Wunsch sind wir Teil einer engagierten Community, die sich für Open Data in allen Bereichen der Mobilität einsetzt. Als Beispiel ist hier das Open Transport Meetup zu nennen, bei dem sich Entwickler*innen und andere Interessierte regelmäßig austauschen und vernetzen. Außerdem konnten wir in unserer Arbeit auf viele Open-Source-Grundlagen zurückgreifen, die von der Community entwickelt wurden und werden – z. B. das Paket gtfs-structures sowie diverse Tools und Erfahrungswerte von Jannis Redmann.
Wenn ihr wissen wollt, wie es mit Dystonse weitergeht, schaut gerne auf unserem Blog vorbei – dort wird es demnächst noch viele spannende Artikel geben – und folgt uns auch gerne auf Twitter.